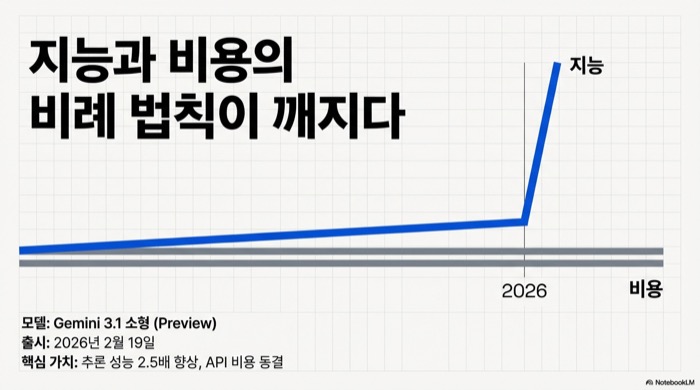
이번 포스팅에서는 Google DeepMind가 2026년 2월 19일에 프리뷰로 공개한 Gemini 3.1 Pro를 정리한다. 추론 벤치마크 ARC-AGI-2에서 77.1%를 찍었다. 전작 Gemini 3 Pro가 31.1%였으니 두 배가 넘는 수치이다. 그런데 API 가격은 입력 100만 토큰당 2달러로 전작과 똑같다. 여러 전문가 모듈 중 필요한 것만 골라 쓰는 Sparse Mixture-of-Experts 아키텍처 기반이며, 텍스트, 이미지, PDF, 오디오, 비디오를 하나의 모델에서 처리하는 멀티모달 모델이다.
한눈에 보는 핵심 정리
Google이 2026년 2월 19일 Gemini 3.1 Pro를 프리뷰로 공개했다. 추론 성능은 전작의 두 배, 가격은 그대로다.
- ARC-AGI-2 77.1% — 전작 Gemini 3 Pro(31.1%) 대비 2.5배
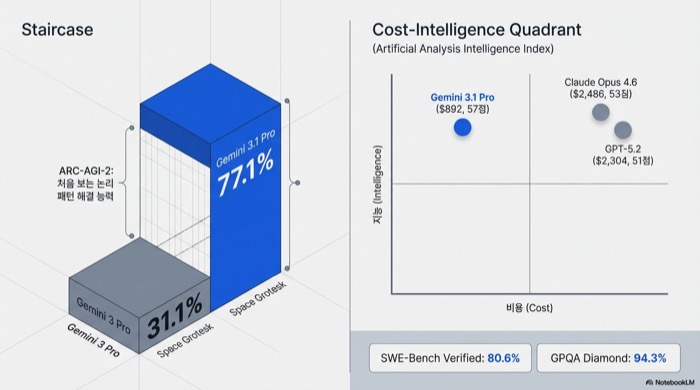
- SWE-Bench Verified 80.6%, GPQA Diamond 94.3%
- API 가격: 입력 $2 / 출력 $12 (100만 토큰당, 전작과 동일)
- 컨텍스트 윈도우: 100만 토큰
- 출력 한도: 64,000 토큰, 초당 108.6 토큰 생성
- 지원 모달리티: 텍스트, 이미지, PDF, 오디오, 비디오
Gemini 3.1 Pro, 추론 성능 2배인데 가격은 그대로라고?
Google DeepMind는 2026년 2월 19일 Gemini 3.1 Pro를 프리뷰 상태로 공개했다. Gemini 시리즈에서 “0.1” 단위의 증분 업데이트는 이번이 처음인데, 그만큼 성능 향상 폭이 기존 관행을 깰 정도로 크다는 의미이다.
Gemini 3.1 Pro는 Sparse Mixture-of-Experts(희소 전문가 혼합) 트랜스포머 아키텍처를 사용한다. 쉽게 말해, 입력 데이터의 종류에 따라 모델 내부의 여러 “전문가” 중 적합한 일부만 골라서 활성화하는 방식이다. 덕분에 모델 전체 파라미터 수는 거대하지만, 한 번의 추론에 실제로 쓰이는 연산량은 상대적으로 적다. Google은 Gemini 3 Deep Think에서 추출한 “핵심 지능(core intelligence)”을 실제 서비스에 맞게 최적화했다고 밝혔다.

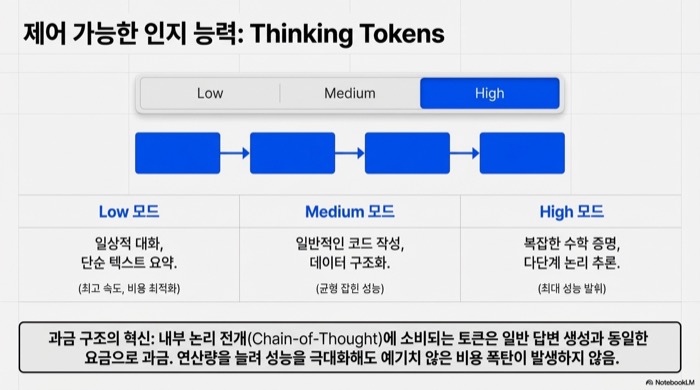
재미있는 기능이 하나 있다. “Thinking Token”이다. Gemini 3.1 Pro는 low, medium, high 세 단계의 추론 모드를 제공한다. 모델이 내부에서 수행하는 체인-오브-사고(chain-of-thought) 과정, 즉 문제를 단계별로 논리적으로 풀어나가는 과정에 소비되는 토큰이 일반 답변 생성과 동일한 요금으로 과금되는 구조이다. 간단한 질문에는 low 모드로 비용을 아끼고, 복잡한 수학 문제나 논리 추론에는 high 모드로 최대 성능을 끌어낼 수 있다.
출력 속도도 빠르다. 최대 64,000 토큰까지 생성 가능하고, 초당 108.6 토큰을 찍는다. 100만 토큰 컨텍스트 윈도우는 약 1시간 분량의 영상이나 700~800페이지 분량의 PDF 문서를 한 번의 프롬프트로 처리할 수 있는 수준이다.

AI 벤치마크 판도를 뒤흔든 77.1%의 진짜 의미
ARC-AGI-2 77.1%가 왜 화제인지부터 짚어 보자. ARC-AGI-2(Abstraction and Reasoning Corpus)는 모델이 훈련 데이터에서 한 번도 본 적 없는 논리 패턴을 풀어야 하는 벤치마크이다. 암기가 아니라 처음 보는 규칙을 스스로 파악하고 적용하는 능력을 측정한다. 전작 Gemini 3 Pro는 여기서 31.1%를 받았다. 한 세대 만에 2.5배가 올랐다.
Artificial Analysis의 Intelligence Index에서 Gemini 3.1 Pro는 57점으로 전체 1위를 차지했다. Claude Opus 4.6은 53점에 비용 2,486달러, GPT-5.2는 51점에 비용 2,304달러가 들었는데, Gemini 3.1 Pro는 892달러로 이들을 넘어섰다. 10개 세부 벤치마크 중 6개에서 최고점을 기록했다.
가격 이야기를 안 할 수 없다. Gemini 3.1 Pro는 입력 100만 토큰당 2달러, 출력 100만 토큰당 12달러로 전작과 완전히 같다. 동일한 작업 기준으로 Claude Opus 4.6(입력 $15, 출력 $75)과 비교하면 약 7배 저렴하다. 흥미로운 부분이 있다. Google에 따르면 추론 시 소비되는 토큰 양이 전작과 비슷하다. 연산을 더 많이 돌려서 점수를 올린 게 아니라, 모델 자체가 똑똑해진 것이다.
물론 모든 영역에서 1위는 아니다. 코딩 분야의 사용자 선호도 순위(LMSys Arena)에서 Gemini 3.1 Pro는 7위에 머물렀다. 자율 에이전트(agent) 작업을 평가하는 GDPval-AA 벤치마크에서도 40%로, Claude Sonnet 4.6(57%)이나 GLM-5(45%)보다 낮은 점수를 받았다. 사람이 직접 평가하는 글쓰기 품질에서도 Chatbot Arena 1위는 여전히 Claude Opus 4.6이 차지하고 있다.
Gemini 3.1 Pro, 지금 당장 어디서 써볼 수 있을까
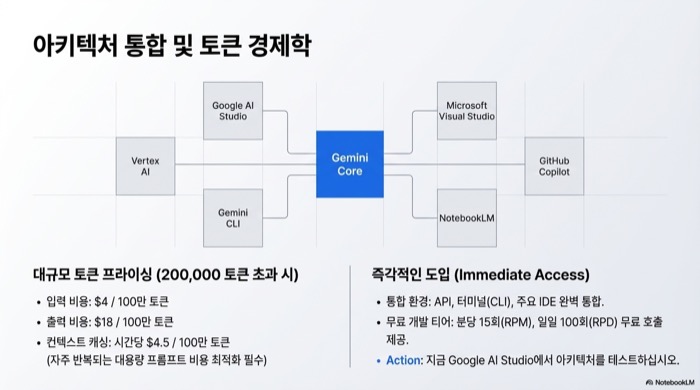
Gemini 3.1 Pro는 이미 여러 경로로 사용할 수 있다. Google AI Studio와 Vertex AI에서 API를 직접 호출할 수 있고, Gemini 앱에서는 AI Pro 또는 Ultra 구독자에게 바로 제공된다. NotebookLM에서도 활성화되었으며, Gemini CLI를 통한 터미널 접근도 가능하다. Microsoft Visual Studio와 GitHub Copilot에 통합되어 개발 환경에서도 곧바로 활용할 수 있다.
무료 사용도 가능하다. 분당 15회(RPM), 하루 100회(RPD)까지 Gemini 3.1 Pro를 무료 티어로 호출할 수 있다. 새로운 AI 모델을 시험해 보거나 개인 프로젝트에 적용해 보기에 충분한 수준이다.
200,000 토큰을 초과하는 대량 입력의 경우 가격이 달라진다. 입력이 100만 토큰당 4달러, 출력이 18달러로 올라가며, 캐시된 토큰은 시간당 100만 토큰당 4.5달러가 부과된다. 자주 반복되는 대용량 프롬프트를 사용하는 경우 캐싱 비용을 고려할 필요가 있다.

3강 체제가 굳어졌다 — 승자는 ‘용도’가 결정한다
2026년 3월 기준, AI 모델 시장은 세 회사가 각자 다른 영역에서 1위를 나눠 갖는 구도가 되었다.
Gemini 3.1 Pro는 범용 추론과 가성비 쪽이다. ARC-AGI-2 77.1%에 Intelligence Index 1위인데, 가격은 경쟁사의 7분의 1이다. Claude Opus 4.6은 코딩(SWE-bench 81.4%)과 글쓰기(Chatbot Arena 1위)에서 앞선다. 2026년 3월 5일에 나온 GPT-5.4는 컴퓨터 자율 조작(OSWorld 75%)과 전문 지식 업무(GDPval 83%)에서 높은 점수를 받았다.
“하나의 최강 모델”은 이제 없다. 추론은 Gemini, 코딩과 글쓰기는 Claude, 컴퓨터 조작은 GPT. 실무에서는 작업에 따라 모델을 바꿔 쓰는 팀이 늘고 있다.
Google은 Gemini 3.1 Pro를 아직 프리뷰로 분류하고 있다. 에이전트 워크플로우 쪽 검증을 더 거친 뒤 정식 출시(GA)할 예정이라고 밝혔다. 정식 버전에서 에이전트 성능이 추가로 올라올 가능성이 있다.
지금까지 Gemini 3.1 Pro를 살펴보았다. 추론 점수는 전작의 두 배, 가격은 그대로, 가성비 기준으로는 현재 가장 눈에 띄는 모델이다. Gemini 3.1 Pro는 무료 티어로 하루 100회까지 호출할 수 있으니, Google AI Studio에서 직접 써보고 체감 성능을 댓글로 공유해 주면 좋겠다.
더 알아보기
- Google 공식 발표 블로그 — Gemini 3.1 Pro
- Gemini 3.1 Pro Model Card (PDF)
- Gemini Developer API 가격 정보
- Artificial Analysis — AI 모델 비교