
이번 포스팅에서는 JDK 24에서 처음 등장한 Java AOT Cache의 동작 원리부터 JDK 26까지의 진화 과정, 그리고 Spring Boot 환경에서의 적용법까지 정리하고자 한다. Project Leyden이라는 이름 아래 3년간 연구된 이 기능은 Spring PetClinic 기준 시작 시간을 4.486초에서 2.604초로 42% 줄였다. Apache Kafka에서는 690ms가 285ms로, 59% 개선이다. GraalVM Native Image와 달리 소스 코드를 건드릴 필요가 없고, JVM 플래그 하나만 추가하면 된다. 이전에 다뤘던 Spring Boot 콜드 스타트 최적화와 함께 적용하면 시너지가 크다.
AppCDS의 한계를 넘어서는 Java AOT Cache
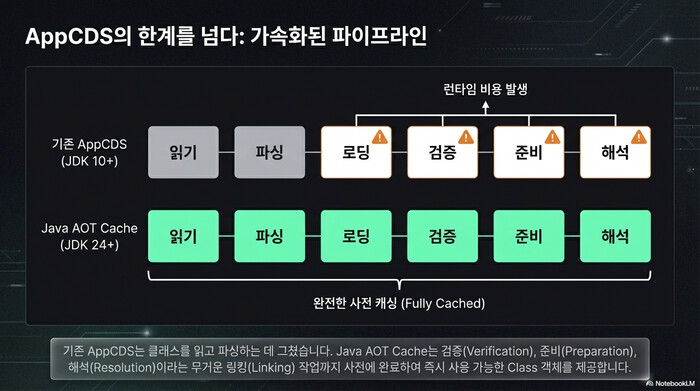
JVM 시작 시간 최적화는 Java 진영의 오래된 숙제다. JDK 10에서 도입된 AppCDS(Application Class Data Sharing)는 클래스 파일을 미리 파싱해 아카이브로 저장하는 방식이었다. 문제는 AppCDS가 클래스를 “읽고 파싱”하는 단계까지만 캐싱한다는 것이다. verification, preparation, resolution 같은 링킹 작업은 매번 런타임에 처리해야 했고, Spring처럼 수천 개의 클래스를 로딩하는 프레임워크에서는 체감 효과가 크지 않았다.
Project Leyden은 이 문제를 풀기 위해 2022년에 시작된 OpenJDK 프로젝트다. Java의 동적 특성을 유지하면서 시작 시간과 메모리를 줄이겠다는 것인데, 그 첫 번째 결과물이 JDK 24에 들어간 JEP 483: Ahead-of-Time Class Loading & Linking이다. 이것이 Java AOT Cache의 시작점이다.
기존 AppCDS와 Java AOT Cache의 차이를 비교하면 다음과 같다.
| 항목 | AppCDS (JDK 10+) | Java AOT Cache (JDK 24+) |
|---|---|---|
| 캐싱 범위 | 읽기 + 파싱 | 읽기 + 파싱 + 로딩 + 링킹 |
| 런타임 작업 | verification, preparation, resolution 필요 | 즉시 사용 가능한 Class 객체 |
| 클래스 로딩 방식 | 개별 클래스 순차 로딩 | 전체 캐시 일괄 로딩 |
| 코드 수정 | 불필요 | 불필요 |
| 시작 시간 개선 | 10~20% | 42~59% |
클래스 로딩 파이프라인이 달라지는 지점
JVM이 클래스를 사용할 수 있는 상태로 만들려면 여러 단계를 거쳐야 한다. 일반적인 클래스 로딩 파이프라인은 다음과 같다.
읽기(Read) → 파싱(Parse) → 로딩(Load) → 검증(Verify) → 준비(Prepare) → 해석(Resolve) → 초기화(Initialize)AppCDS는 이 파이프라인에서 “읽기 → 파싱”까지만 사전에 수행한다. 클래스 파일의 바이트코드를 읽고 내부 표현으로 변환하는 작업을 캐싱하지만, 로딩 이후의 단계는 매번 런타임에 처리해야 한다.
Java AOT Cache는 “읽기 → 파싱 → 로딩 → 검증 → 준비 → 해석”까지 모두 사전에 수행한다. Training Run이라는 한 번의 사전 실행을 통해 애플리케이션이 실제로 사용하는 클래스를 파악하고, 해당 클래스들을 완전히 링킹된 상태로 캐시에 저장한다. 이후 프로덕션 실행에서는 캐시에 저장된 Class 객체를 바로 사용하므로, 클래스 계층 구조를 탐색하고 심볼릭 참조를 해석하는 비용이 사라진다.
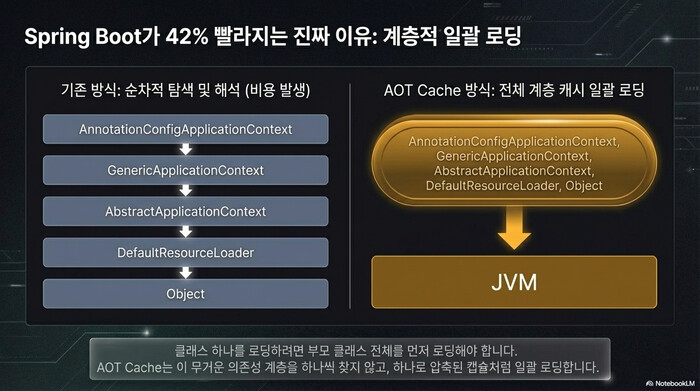
여기서 한 가지 짚고 넘어갈 부분이 있다. 클래스 하나를 로딩하려면 그 상위 클래스 전체를 먼저 로딩해야 한다. Spring의 AnnotationConfigApplicationContext를 쓰려면 GenericApplicationContext, AbstractApplicationContext, DefaultResourceLoader, Object까지 줄줄이 따라온다. Java AOT Cache는 이 전체 계층을 한꺼번에 캐시에 넣고 일괄 로딩한다. 클래스를 하나씩 찾아가며 해석하는 비용이 사라지는 것이다.
JDK 24의 3단계 워크플로우로 AOT Cache 직접 만들기
JDK 24에서 Java AOT Cache를 사용하려면 세 가지 명령어를 순서대로 실행해야 한다. 코드 수정은 전혀 필요 없다.
# 1단계: Training Run — 애플리케이션의 AOT 설정 기록
java -XX:AOTMode=record \
-XX:AOTConfiguration=app.aotconf \
-jar my-app.jar
# 2단계: Cache 생성 — 기록된 설정으로 캐시 어셈블
java -XX:AOTMode=create \
-XX:AOTConfiguration=app.aotconf \
-XX:AOTCache=app.aot \
-jar my-app.jar
# 3단계: Production 실행 — 캐시를 사용해 빠르게 시작
java -XX:AOTCache=app.aot \
-jar my-app.jar1단계 Training Run에서는 애플리케이션을 실제로 한 번 실행하면서 어떤 클래스가 로딩되는지를 기록한다. 이 과정에서 생성되는 app.aotconf 파일에는 클래스 목록과 로딩 순서가 담긴다. 2단계에서는 이 설정을 바탕으로 클래스들을 로딩하고 링킹한 뒤 .aot 캐시 파일로 저장한다. 3단계 프로덕션 실행에서는 -XX:AOTCache 플래그만 추가하면 캐시에서 즉시 Class 객체를 가져와 사용한다.
간단한 Java 애플리케이션으로 Java AOT Cache의 효과를 직접 확인해 볼 수 있다.
import java.time.Instant;
import java.util.stream.IntStream;
public class StartupBenchmark {
public static void main(String[] args) {
long start = ProcessHandle.current().info().startInstant()
.orElse(Instant.now()).toEpochMilli();
long now = System.currentTimeMillis();
// 의도적으로 여러 JDK 클래스를 로딩
var list = IntStream.range(0, 1000)
.mapToObj(String::valueOf)
.toList();
System.out.printf("시작 시간: %dms, 로딩된 항목: %d%n",
now - start, list.size());
}
}위 코드는 JVM 프로세스의 시작 시각과 main 메서드 진입 시각의 차이를 측정한다. IntStream, String, List 등 여러 JDK 클래스를 의도적으로 사용해 클래스 로딩 비용을 확인할 수 있다. Java AOT Cache를 적용하면 이 값이 눈에 띄게 줄어든다.
# AOT Cache 없이 실행
$ java StartupBenchmark
시작 시간: 89ms, 로딩된 항목: 1000
# AOT Cache 적용 후 실행
$ java -XX:AOTCache=app.aot StartupBenchmark
시작 시간: 34ms, 로딩된 항목: 1000위 결과처럼 단순한 애플리케이션에서도 시작 시간이 89ms에서 34ms로 약 62% 단축되는 것을 확인할 수 있다. 로딩할 클래스가 많은 대형 프레임워크에서는 이 차이가 훨씬 더 극적으로 나타난다.
Training Run에서 한 가지 주의할 점이 있다. 프로덕션 환경과 동일한 classpath를 사용해야 한다는 것이다. JAR 파일의 순서가 다르거나, Training Run에 포함되지 않은 JAR가 프로덕션에서 추가되면 캐시가 무시되고 일반 로딩으로 폴백한다. 캐시가 정상적으로 적용되는지는 -Xlog:cds 옵션으로 로그를 확인해 볼 수 있다. 캐시 로딩 실패 시 JVM은 일반 로딩으로 자동 폴백하므로, 로그를 통해 설정 오류를 감지해야 한다.
JDK 25에서 3단계가 2단계로 줄었다
JDK 24의 3단계 워크플로우는 잘 동작하지만, CI/CD 파이프라인에서 JVM을 세 번 실행하는 것은 번거롭다. JEP 514가 JDK 25에서 이 문제를 해결했다.
# JDK 25: 2단계 워크플로우
# 1단계: Training + Cache 생성을 한 번에
java -XX:AOTCacheOutput=app.aot \
-jar my-app.jar
# 2단계: Production 실행
java -XX:AOTCache=app.aot \
-jar my-app.jar-XX:AOTCacheOutput 하나로 Training Run과 Cache 생성이 동시에 처리된다. JVM이 애플리케이션을 실행하면서 클래스 로딩 정보를 기록하고, 종료 시점에 캐시를 생성한다. 기존의 -XX:AOTMode=record와 -XX:AOTMode=create가 하나로 합쳐진 것이다.
다만 이 방식은 힙 메모리를 2배로 사용한다. 애플리케이션 힙과 캐시 생성 힙이 동시에 필요하기 때문이다. -Xmx2g를 지정했다면 실제로 약 4GB가 필요하므로, CI 서버의 메모리 한도를 확인해야 한다.
JDK 25에는 워크플로우 간소화 말고도 JEP 515: Ahead-of-Time Method Profiling이 들어갔다. JEP 483이 시작 시간을 줄였다면, JEP 515는 워밍업 시간을 줄인다.
# JDK 25에서는 AOT Cache에 메서드 프로파일링 데이터가 자동 포함된다
java -XX:AOTCacheOutput=app.aot -jar my-app.jar
# 생성된 캐시에는 클래스 데이터 + 메서드 호출 빈도 정보가 함께 저장된다위 명령으로 생성된 Java AOT Cache에는 클래스 로딩 데이터뿐 아니라, Training Run 중 어떤 메서드가 자주 호출되었는지에 대한 프로파일링 정보도 들어간다. 프로덕션에서 JIT 컴파일러가 이 데이터를 읽으면, 자체 프로파일 수집을 기다리지 않고 바로 핫 메서드를 네이티브 코드로 컴파일할 수 있다. 애플리케이션이 최고 성능에 도달하기까지의 시간, 즉 워밍업이 줄어드는 것이다.
JDK 26에서 ZGC도 Java AOT Cache를 쓸 수 있게 되었다
JDK 24~25까지 Java AOT Cache는 Serial GC와 G1 GC에서만 동작했다. ZGC는 “colored pointer”라는 기법으로 포인터 자체에 메타데이터를 인코딩하는데, 이것이 캐시의 메모리 주소 직접 참조 방식과 충돌했기 때문이다.
JEP 516: Ahead-of-Time Object Caching with Any GC가 JDK 26에서 이 문제를 풀었다. 객체 참조를 물리적 메모리 주소 대신 논리적 인덱스로 저장하고, 시작 시점에 실제 주소로 매핑하는 방식이다. 이로 인해 두 가지 캐시 포맷이 생겼다.
| 캐시 포맷 | 동작 방식 | 지원 GC | 성능 |
|---|---|---|---|
| GC-specific | 메모리 직접 매핑 | Serial, G1 | 약 28% 시작 시간 개선 |
| GC-agnostic | 스트리밍 + 주소 리매핑 | Serial, G1, ZGC, Shenandoah | 약 26% 시작 시간 개선 |
Spring PetClinic 기준으로 두 포맷의 성능 차이는 약 2%p다. 캐시 크기도 123.8MB vs 124MB로 거의 같다. ZGC를 쓸 수 있다는 유연성 대비 성능 손실이 미미하다.
JDK 26에서 또 하나 달라진 점은 기본 AOT 캐시가 JDK 자체에 포함되기 시작했다는 것이다. Training Run을 전혀 하지 않아도 JDK 내장 클래스에 대한 기본 캐시가 적용되므로, JDK 26으로 올리기만 해도 모든 애플리케이션에서 소폭의 시작 시간 개선이 생긴다.
Spring Boot 4 + JDK 25에서 Java AOT Cache 적용하기
Spring Boot 4는 Java AOT Cache를 공식 지원한다. 아래 예시는 JDK 25의 2단계 워크플로우(-XX:AOTCacheOutput) 기준이다. JDK 24를 사용하는 경우 앞서 설명한 3단계 워크플로우로 대체하면 된다. Spring Boot 공식 문서에 나온 절차를 따르면 된다.
먼저 Fat JAR를 Extracted 형태로 풀어야 한다. Java AOT Cache는 classpath의 JAR 파일 순서에 민감한데, Spring Boot의 Layered JAR 형식 그대로 쓰면 캐시 효율이 떨어질 수 있다.
# 1단계: Fat JAR를 extracted 형태로 풀기
java -Djarmode=tools -jar my-spring-app.jar extract --destination application
cd application위 명령은 Spring Boot의 내장 도구 모드를 사용해 Fat JAR를 풀어놓는다. application 디렉터리 아래에 lib 폴더와 애플리케이션 JAR가 분리되며, 이 상태에서 AOT Cache를 생성해야 classpath가 일관되게 유지된다.
# 2단계: Training Run으로 AOT Cache 생성
java -XX:AOTCacheOutput=app.aot \
-Dspring.context.exit=onRefresh \
-jar my-app.jar-Dspring.context.exit=onRefresh는 Spring Context가 Refresh(모든 빈 초기화)를 완료한 시점에 애플리케이션을 종료시키는 프로퍼티다. 이 설정이 없으면 Training Run이 애플리케이션을 실제로 가동시켜 HTTP 요청을 기다리게 된다. Context Refresh 시점까지의 클래스 로딩이 시작 시간의 대부분을 차지하므로, 이 시점에 종료해도 충분한 캐시를 확보할 수 있다.
# 3단계: Production 실행
java -XX:AOTCache=app.aot -jar my-app.jar위 명령으로 프로덕션 환경에서 Java AOT Cache가 적용된 상태로 애플리케이션을 시작한다. 캐시 파일은 Training Run에 사용한 것과 동일한 JDK 버전, 동일한 OS/아키텍처에서만 유효하다.
Gradle 빌드 파이프라인에 통합하려면 다음과 같이 Dockerfile에 Training Run 단계를 추가하는 것이 일반적이다. Spring Boot Docker 이미지 최적화에서 다뤘던 Multi-stage 빌드 패턴을 그대로 활용할 수 있다.
FROM eclipse-temurin:25-jre AS builder
WORKDIR /app
COPY build/libs/my-spring-app.jar app.jar
# Fat JAR 추출 — extracted/ 아래에 lib/과 my-spring-app.jar가 생성된다
RUN java -Djarmode=tools -jar app.jar extract --destination extracted
# Training Run으로 AOT Cache 생성 (JDK 25+ 2단계 워크플로우)
WORKDIR /app/extracted
RUN java -XX:AOTCacheOutput=app.aot \
-Dspring.context.exit=onRefresh \
-jar my-spring-app.jar
FROM eclipse-temurin:25-jre
WORKDIR /app
COPY --from=builder /app/extracted /app
# AOT Cache를 사용한 프로덕션 실행
ENTRYPOINT ["java", "-XX:AOTCache=app.aot", "-jar", "my-spring-app.jar"]Multi-stage 빌드의 builder 단계에 Training Run을 넣으면, 최종 이미지에는 캐시 파일과 애플리케이션만 남는다. 기존 Spring Boot Docker 빌드에 RUN java -XX:AOTCacheOutput=... 한 줄만 추가하면 되는 구조다.
DB 없이 Training Run을 돌릴 수 있을까
실제 프로젝트에서 Java AOT Cache를 적용하려고 하면 곧바로 부딪히는 문제가 있다. Training Run 중에 애플리케이션이 DB, Redis, Kafka 같은 외부 인프라에 연결을 시도한다는 것이다. CI 파이프라인에서 Training Run을 돌리려면 이 인프라들을 다 띄워야 하나? 결론부터 말하면, 방법이 있다.
-Dspring.context.exit=onRefresh가 이 문제의 절반을 해결해 준다. 이 플래그를 사용하면 Spring Context가 Refresh까지만 진행하고 lifecycle은 시작하지 않는다. 즉 Kafka Consumer, HTTP 서버 포트, 스케줄러 같은 SmartLifecycle 빈은 실행되지 않는다. 하지만 DataSource나 RedisConnectionFactory 같은 빈은 Context Refresh 과정에서 생성되기 때문에, 여전히 DB 연결이 필요하다.
나머지 절반은 Spring Profile로 해결한다. Training 전용 프로파일을 만들어 실제 인프라 대신 embedded 대체제를 사용하는 것이다.
# application-training.yml
spring:
datasource:
url: jdbc:h2:mem:training
driver-class-name: org.h2.Driver
jpa:
database-platform: org.hibernate.dialect.H2Dialect
hibernate:
ddl-auto: create # 스키마 자동 생성
data:
redis:
host: localhost
port: 6379 # lifecycle이 안 뜨므로 실제 연결은 시도되지 않을 수 있음위 설정은 실제 PostgreSQL이나 MySQL 대신 H2 인메모리 DB를 사용하는 Training 전용 프로파일이다. JPA 관련 클래스 로딩은 동일하게 이루어지면서, 외부 DB 없이 Training Run을 완료할 수 있다. Redis나 Kafka는 lifecycle이 시작되지 않으므로 실제 연결이 성립하지 않는 경우가 많지만, ConnectionFactory 빈 생성 시 연결을 시도하는 드라이버가 있다면 해당 auto-configuration을 제외해야 한다.
# Training Run with training profile
java -XX:AOTCacheOutput=app.aot \
-Dspring.profiles.active=training \
-Dspring.context.exit=onRefresh \
-jar my-app.jar
# Production Run (training profile 없이 실행)
java -XX:AOTCache=app.aot -jar my-app.jar위 명령에서 Training Run은 training 프로파일로 H2를 사용하고, 프로덕션 실행에서는 기본 프로파일의 실제 DB를 사용한다. 캐시에 저장되는 것은 Class 객체이므로, H2 드라이버로 로딩된 JPA/Hibernate 클래스와 실제 DB 드라이버로 로딩되는 클래스가 동일하다면 캐시는 정상 동작한다.
한 가지 주의할 점은, Training Run에서 H2를 사용하면 H2 드라이버 관련 클래스가 캐시에 포함된다는 것이다. 프로덕션에서 사용하지 않는 클래스가 캐시에 들어가므로 캐시 크기가 약간 늘어난다. inside.java의 공식 가이드에서도 “mock 의존성을 사용하면 불필요한 캐시 항목이 추가될 수 있다”고 언급하고 있다. 실무에서는 이 정도의 오버헤드는 무시할 수준이다.
auto-configuration 제외가 필요한 경우 다음과 같이 처리할 수 있다.
# application-training.yml — 특정 auto-configuration 제외
spring:
autoconfigure:
exclude:
- org.springframework.boot.autoconfigure.data.redis.RedisAutoConfiguration
- org.springframework.boot.autoconfigure.kafka.KafkaAutoConfiguration위 설정으로 Redis와 Kafka의 auto-configuration을 완전히 제외하면, 해당 ConnectionFactory 빈이 생성되지 않으므로 인프라 연결 시도 자체가 사라진다. 다만 이 경우 Redis/Kafka 관련 클래스가 캐시에 포함되지 않으므로, 프로덕션에서 해당 클래스들은 일반 로딩으로 처리된다. 애플리케이션에서 Redis/Kafka를 많이 사용하지 않는다면 시작 시간에 미치는 영향은 미미하다.
Buildpack으로 Dockerfile 없이 AOT Cache 적용하기
앞서 Dockerfile에 Training Run을 직접 추가하는 방법을 살펴봤다. 하지만 Spring Boot의 Cloud Native Buildpacks를 사용하고 있다면 훨씬 간단한 방법이 있다. Paketo Spring Boot Buildpack v5.35.0부터 Java AOT Cache를 자체 지원하며, 환경 변수 하나만 설정하면 된다.
// build.gradle.kts — Gradle 설정
tasks.named<org.springframework.boot.gradle.tasks.bundling.BootBuildImage>("bootBuildImage") {
environment.set(mapOf(
"BP_JVM_AOTCACHE_ENABLED" to "true" // AOT Cache 자동 생성
))
}위 설정을 추가한 뒤 ./gradlew bootBuildImage를 실행하면, Buildpack이 내부적으로 다음 과정을 자동으로 처리한다. 먼저 애플리케이션의 Training Run을 수행하고, 생성된 AOT Cache 파일을 이미지 레이어에 포함시킨 뒤, 컨테이너 시작 시 -XX:AOTCache 플래그를 자동으로 추가한다. Dockerfile을 작성하거나 Training Run 명령어를 직접 관리할 필요가 없다.
Maven에서는 pom.xml에 다음과 같이 설정한다.
<!-- pom.xml — Maven 설정 -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<image>
<env>
<!-- AOT Cache 자동 생성 및 적용 -->
<BP_JVM_AOTCACHE_ENABLED>true</BP_JVM_AOTCACHE_ENABLED>
</env>
</image>
</configuration>
</plugin>위 설정 후 mvn spring-boot:build-image로 이미지를 빌드하면 Gradle과 동일하게 Java AOT Cache가 자동 적용된다. Training Run, 캐시 생성, 런타임 플래그 설정이 모두 Buildpack 내부에서 처리된다.
Training Run 중에 DB 연결 등의 문제가 발생하면, TRAINING_RUN_JAVA_TOOL_OPTIONS 환경 변수로 Training Run 전용 JVM 옵션을 지정할 수 있다. 이 값은 Training Run에서만 사용되고, 프로덕션 실행에는 영향을 주지 않는다.
// Training Run에서만 적용되는 JVM 옵션 설정
tasks.named<org.springframework.boot.gradle.tasks.bundling.BootBuildImage>("bootBuildImage") {
environment.set(mapOf(
"BP_JVM_AOTCACHE_ENABLED" to "true",
// Training Run 전용: training 프로파일 사용
"TRAINING_RUN_JAVA_TOOL_OPTIONS" to "-Dspring.profiles.active=training"
))
}위 설정에서 TRAINING_RUN_JAVA_TOOL_OPTIONS에 -Dspring.profiles.active=training을 지정하면, 앞서 다뤘던 Training 프로파일(H2 인메모리 DB 사용)이 Buildpack의 Training Run에서도 적용된다. 실제 인프라 없이 Buildpack만으로 Java AOT Cache가 포함된 프로덕션 이미지를 만들 수 있는 것이다.
한 가지 주의할 점은 Java 25 이상이 필요하다는 것이다. Buildpack은 내부적으로 JDK 25의 -XX:AOTCacheOutput 플래그를 사용하므로, JDK 24에서는 동작하지 않는다. Paketo 빌더의 JDK 버전이 25 이상인지 확인해야 한다.
Kafka 59%, PetClinic 42% — 실측 벤치마크

공개된 벤치마크 결과를 바탕으로 Java AOT Cache의 성능 개선 수치를 정리했다.
| 애플리케이션 | 캐시 없음 | AOT Cache | 개선율 | 개시 크기 |
| Spring PetClinic | 4,486ms | 2,604ms | 43% | ~124MB |
| Apache Kafka 4.0 | 690ms | 285ms | 59% | 66MB |
| Apache Flink | 1,876ms | 913ms | 51% | – |
Spring PetClinic은 JDK 23에서 4.486초, JDK 24 + Java AOT Cache에서 2.604초로 시작된다. 42% 개선인데, Gunnar Morling의 분석에 따르면 개선분의 상당 부분이 클래스 파일 읽기/파싱 캐싱에서 나오고, 링킹 최적화에서 나오는 추가 개선분도 명확히 존재한다. 링킹만 제거해도 약 47%의 시작 시간 개선이 가능했다는 테스트 결과가 있다.
Apache Kafka 4.0에서는 690ms가 285ms로 59% 줄었다. Kafka는 시작 시 수많은 클래스를 로딩하면서 복잡한 의존성 그래프를 해석해야 하는데, 이런 구조에서 링킹 캐싱의 효과가 가장 크게 나타난다.
GraalVM Native Image와의 비교

같은 Kafka 애플리케이션을 GraalVM Native Image로 빌드하면 시작 시간이 118ms까지 줄어든다. Java AOT Cache의 285ms보다 2.4배 빠르다. 하지만 GraalVM Native Image에는 다음과 같은 트레이드오프가 있다.
| 항목 | Java AOT Cache | GraalVM Native Image |
|---|---|---|
| 시작 시간 (Kafka) | 285ms | 118ms |
| 코드 수정 | 불필요 | 리플렉션 메타데이터 등 설정 필요 |
| 빌드 시간 | 수 초 (Training Run) | 수 분~수십 분 |
| 런타임 동적 기능 | 전체 지원 | 제한적 (closed-world 가정) |
| 최고 성능(throughput) | JIT 최적화로 높음 | AOT 컴파일로 제한적 |
| 적용 난이도 | JVM 플래그 추가만 | 빌드 도구 변경, 테스트 필요 |
서버리스나 Function-as-a-Service 환경에서는 GraalVM Native Image가 여전히 유리하다. 반면 기존 컨테이너 배포에서 스케일링 속도를 올리고 싶은데 코드 수정은 부담스러운 경우, Java AOT Cache가 맞는다. 상황에 따라 선택하면 된다.
프로덕션 적용 전에 확인할 것들

Java AOT Cache를 실제로 쓰려면 몇 가지 제약을 알아둬야 한다. JDK 26에서도 여전히 유효한 것들이다.
classpath 일치가 가장 기본이다. Training Run과 프로덕션에서 JAR 파일이 동일해야 하고, 순서까지 같아야 한다. 와일드카드(*)로 classpath를 지정하면 순서가 보장되지 않으므로 쓸 수 없다. 프로덕션에서 JAR를 더 추가하는 것은 괜찮지만, Training Run에 있던 JAR가 프로덕션에서 빠지면 캐시가 무효화된다.
# 캐시 적용 여부를 로그로 확인
java -Xlog:cds -XX:AOTCache=app.aot -jar my-app.jar
# 로그에서 "Opened AOT cache" 메시지가 나오면 정상 적용
# classpath 불일치 등의 문제가 있으면 폴백 로그가 출력된다위 명령에서 -Xlog:cds는 CDS/AOT 캐시 관련 로그를 출력하는 옵션이다. 캐시가 적용되지 않는 상황(classpath 불일치, JDK 버전 차이 등)에서 JVM은 에러 없이 일반 로딩으로 폴백하기 때문에, 로그를 통해 실제로 캐시가 사용되는지 확인하는 습관이 필요하다.
사용자 정의 ClassLoader 미지원이 현재 가장 아쉬운 제약이다. JVM의 내장 클래스 로더(bootstrap, platform, application)로 로딩되는 클래스만 캐싱된다. Apache Flink처럼 자체 ClassLoader를 쓰는 프레임워크에서는 해당 클래스가 캐시에 안 들어간다. JEP 문서에 향후 해소될 수 있다고 적혀 있긴 하다.
메모리 요구량도 챙겨야 한다. JDK 25의 2단계 워크플로우를 쓰면 Training Run 중에 애플리케이션 힙과 캐시 생성 힙이 동시에 뜬다. -Xmx2g를 설정했다면 CI 환경에서는 실제로 약 4GB가 필요하다.
JDK 버전과 아키텍처도 맞아야 한다. x86_64에서 만든 캐시를 aarch64에서 못 쓰고, JDK 25 캐시를 JDK 26에서 못 쓴다. Docker 빌드에서 Training Run과 프로덕션의 베이스 이미지를 통일해야 하는 이유다.
JDK 24~26 Project Leyden 로드맵 정리

Java AOT Cache는 JDK 버전이 올라갈 때마다 쓸 수 있는 범위가 넓어지고 있다. 각 버전에서 추가된 JEP를 정리하면 다음과 같다.
| JDK 24 | JEP 483: AOT Class Loading & Linking – 3단계 워크플로우 (record -> create -> run) – Serial GC, G1 GC만 지원 – Spring PetClinic 42% 시작 시간 개선 |
| JDK 25 | JEP 514: AOT Command Line Ergonomics – 2단계 워크플로우 (-XX:AOTCacheOutput) JEP 515: AOT Method Profiling – 워밍업 시간 단축 (JIT 프로파일 사전 제공) |
| JDK 26 | JEP 516: AOT Object Caching with Any GC – ZGC, Shenandoah 지원 – 기본 AOT 캐시 JDK에 포함 – GC-agnostic 캐시 포맷 도입 |
JDK 24에서 기능을 증명하고, JDK 25에서 사용법을 간소화하면서 워밍업까지 커버하고, JDK 26에서 GC 제한을 해소하며 기본값으로 채택한 흐름이다. 다음 단계로는 사용자 정의 ClassLoader 지원과 AOT 컴파일 캐싱 쪽으로 갈 가능성이 높다.
마치며
지금까지 Java AOT Cache의 동작 원리와 JDK 24~26 진화 과정, Spring Boot 적용법을 정리해 보았다.
솔직히 GraalVM Native Image를 실무에 적용하다가 리플렉션 메타데이터 삽질, 써드파티 호환성 확인, 20분 넘는 빌드 시간에 지친 경험이 있다면 Java AOT Cache가 반가울 것이다. JVM 플래그 하나면 된다. Kafka에서 59%, PetClinic에서 42% 개선이 코드 한 줄 수정 없이 나온다. 다음 JDK 업그레이드 때 Dockerfile에 Training Run 한 줄을 끼워 넣어 보는 것을 권한다. 생각보다 간단하고, 효과는 즉시 확인된다.