
Spring Boot로 애플리케이션을 만들든 대규모 배치 처리를 하든 간에 List, Map, Set과 같은 자바 컬렉션은 거의 모든 부분에서 사용된다고 해도 과언이 아니다. 이번 포스팅에서는 자바 Collection에 대해서 정리해보고자 한다.
Java Collection Framework(이하 JCF)는 JDK 1.2부터 도입되어 데이터를 그룹으로 다루기 위해 표준화된 아키텍처를 제공한다. 프레임워크라고 불리는 이유는 바로 이 때문이다.
JCF는 크게 두개의 뿌리로 나눈다. 하나는 객체의 그룹을 다루는 java.util.Collection 인터페이스이고 다른 하나는 키(Key)와 값(Value)를 다루는 java.util.Map 인터페이스다. Map은 엄밀히 말해 Collection을 상속받지 않지만 JCF의 중요한 한 축을 담당한다.
Collection 인터페이스
Collection 인터페이스는 모든 컬렉션이 갖추어야 할 가장 기본적인 동작을 정의한다. 이를 상속받는 주요 인터페이스는 다음과 같다.
- List(리스트): 순서가 있는 데이터의 집합이다. 데이터의 중복을 허용하며, 인덱스(Index)를 통해 데이터에 접근할 수 있어 시퀀스라고도 불린다. 대표적인 구현체로 ArrayList, LinkedList, Vector(레거시)가 있다.
- Set(셋): 수학의 개념을 모델링했다. 데이터의 중복을 허용하지 않는다. 순서를 보장하지 않는 것이 일반적이나 구현체에 따라 순서를 보장하기도 한다. 대표적으로 HashSet, TreeSet이 있다.
- Queue(큐): 처리를 기다리는 요소를 보관하는 용도로 설계되었다. 일반적으로 FIFO(First-In-First-Out) 구조를 가지지만, 우선순위 큐(PriorityQueue)처럼 우선순위에 따라 순서가 결정되기도 한다.
- Deque(덱): ‘Double Ended Queue’의 약자로 양쪽 끝에서 요소를 추가하거나 제거할 수 있는 자료구조다. Queue를 상속받았지만 Queue와는 쓰임새가 꽤 달라서 별도의 뿌리로 이해하면 좋다. 스택(Stack)과 큐(Queue)의 기능을 모두 수행할 수 있어 활용도가 높다.
| 인터페이스 | 역할 및 특징 | 순서(Order) | 중복 |
| List | 순서가 있는 저장소(배열과 유사) | 입력 순서 보장 | 허용 |
| Set | 집합 (순서보다 유니크한 값이 중요) | 순서 없음 (LinkedHashSet, TreeSet은 예외) | 허용안함 |
| Queue | 대기열 (FIFO) | 입력 순서 보장 | 허용 |
| Deque | 양쪽 끝이 뚫린 큐 (Stack + Queue) | 입력 순서 보장 (양쪽 끝에서 조작 가능) | 허용 |
Map 인터페이스
Map은 키(Key)를 값(Value)에 매핑하는 객체다. 키는 중복될 수 없으며 하나의 키는 하나의 값에만 매핑된다. Collection 인터페이스를 상속받지는 않지만 keySet(), values(), entrySet() 메서드를 통해 컬렉션 뷰를 제공함으로써 컬렉션과 유기적으로 연결된다.
레거시 컬렉션
초기버전 (JDK 1.0)에서 사용되던 Vector, Stack, Hashtable과 같은 클래스도 여전히 존재한다. 하지만 이들은 모든 메서드에 동기화(Synchronized)가 걸려 있어 멀티스레드 환경이 아닌 곳에서는 불필요한 성능 저하를 유발한다. 따라서 현재는 다음과 같이 대체하여 사용하는 것이 권장된다.
| 레거시 | 대체클래스 | 설명 |
| Vector | ArrayList | 동기화 제거, 성능 이점 |
| HashTable | HashMap | 동기화 제거, null 키/값 허용 |
| Stack | ArrayDeque | 일관된 API, 성능 우수 |
Vector -> ArrayList, HashTable -> HashMap, Stack -> ArrayDeque 대체는 불필요한 동기화 로직을 제거함으로써 성능상의 이점을 가져오지만 스레드 안전하지 않기 때문에 멀티스레드 환경에서 공유하는 것은 위험하다.
이 경우에는 java.util.concurrent 패키지의 클래스들을 사용해야 한다.
List 인터페이스
개발자가 가장 많이 사용하는 List 인터페이스의 구현체인 ArrayList와 LinkedList를 비교하는 것은 애플리케이션의 성능을 좌우하는 중요한 부분이다.
ArrayList
ArrayList는 이름 그대로 배열(Array)을 기반으로 한 리스트다. 내부적으로 Object elementData라는 배열을 가지고 데이터를 관리한다.
자바의 배열은 생성시 크기가 고정되지만 ArrayList는 동적으로 크기를 변경할 수 있다. 처음 설정한 capacity가 차면 더 큰 배열을 새로 만들고 기존 데이터를 복사하는 원리다. 이 때 새로운 배열을 얼마나 더 크게 만들것인가가 중요한데 JDK의 ArrayList는 기본적으로 1.5배(50%)씩 크기를 늘린다.
old Capacity + (oldCapacity >> 1)ArrayList의 가장 큰 장점은 인덱스를 통한 조회 속도가 O(1)이라는 점이다. 배열은 메모리 상에서 연속적으로 위치하기 때문에 인덱스의 주소를 시작 주소 + (인덱스 * 데이터 크기)라는 단순한 수식으로 위치를 바로 찾을 수 있기 때문이다. 이는 데이터가 100개든 100만개든 조회 속도가 동일함을 의미한다.
LinkedList
LinkedList는 모든 노드들이 서로 연결된 구조다. 각 노드는 데이터와 다음 노드의 주소(next), 이전 노드의 주소(prev)를 가지고 있다. (Doublely Linked List)
LinkedList는 중간에 삽입/삭제가 빠르다는 장점이 있다. ArrayList는 중간에 데이터를 넣으려면 뒤의 데이터들을 한칸씩 밀어야 해서 O(n)이 걸리지만 LinkedList는 앞뒤 노드의 연결 고리만 바꿔주면 되므로 O(1)이 걸린다.
하지만 여기에는 함정이 있다.
현대의 컴퓨터 아키텍처에서 CPU는 메모리(RAM)에서 데이터를 가져올 때 필요한 데이터 하나만 가져오지 않고 캐시 라인(Cache Line) 이라는 단위(보통 64바이트)로 주변 데이터까지 덩어리로 가져와 CPU 내부의 캐시에 저장한다. (Cache Locality)
- ArrayList의 경우: 데이터가 메모리에 연속적으로 저장되어 있기 때문에 그 뒤의 요소들도 함께 캐시로 딸려온다. 순차적으로 데이터를 읽을 때 이미 데이터가 캐시에 있을 확률이 높기 때문에 빠르다.
- LinkedList의 경우: 데이터(노드)가 힙 메모리의 이곳저곳에 흩어져 있기 때문에 논리적으로는 연결되어 있지만 물리적으로는 멀리 떨어져 있을 수 있다. 따라서 다음 노드로 이동할 때마다 CPU는 캐시에 없는 데이터를 메모리에서 새로 가져와야 하기 때문에 이로 인해 CPU 파이프라인이 멈추고 성능이 저하될 수 있다.
실제 벤치마크를 돌려보면 요소의 삽입/삭제조차도 리스트의 크기가 엄청나게 크지 않은 이상 ArrayList가 LinkedList보다 빠른 경우가 많다. LinkedList에서 삽입 위치를 찾기 위해 탐색하는 과정 자체가 O(n)이며 이 탐색 과정에서 캐시 효율이 나쁘기 때문이다. 따라서 특별한 이유가 없다면 항상 ArrayList를 기본적으로 사용하는 것이 좋다.
위 내용은 아래 링크들을 참고하기 바란다.
https://stackoverflow.com/questions/79594341/arraylist-vs-linkedlist-in-terms-of-cache-locality
https://www.geeksforgeeks.org/dsa/why-arrays-have-better-cache-locality-than-linked-list/
https://can-ozkan.medium.com/arraylist-vs-linkedlist-88022088fdef
Map과 Set의 내부
데이터의 유일성을 보장하는 Set과 키-값쌍을 관리하는 Map은 내부적으로 유사한 구조를 가진다. 사실 HashSet은 내부적으로 HashMap을 사용하여 구현되어 있고 Set의 값은 HashMap의 키로 저장되고 HashMap의 값은 PRESENT라는 더비 객체가 들어간다. 다음은 HashSet 클래스의 멤버변수 선언부분이다.
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();HashMap의 진화: LinkedList에서 Red-Black 트리로
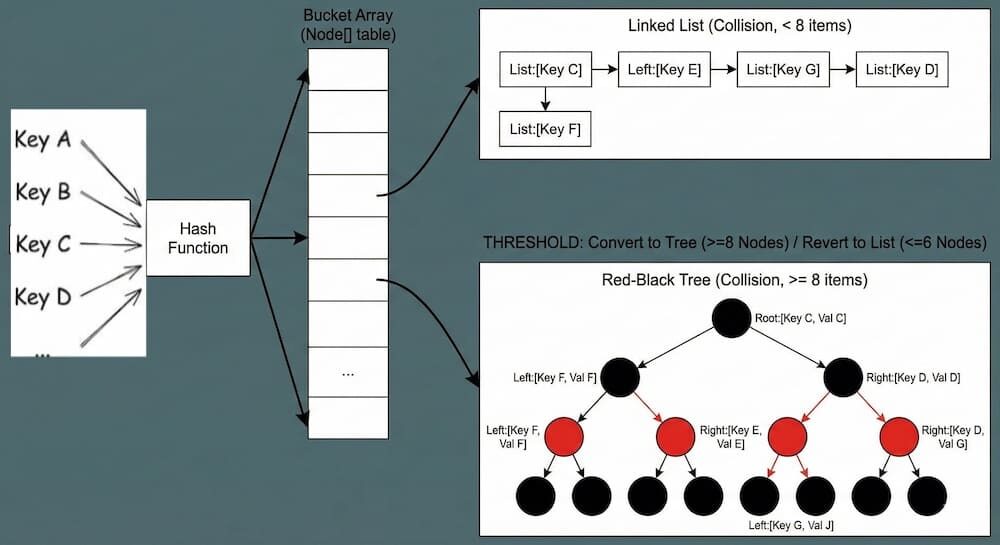
HashMap은 해시 버킷(Hash Bucket)이라는 배열을 사용한다. 해시 버킷은 해시 테이블(HashMap)의 가장 기본이 되는 저장소 단위를 말한다. 쉽게 말해 데이터가 실제로 담기는 서랍이라고 생각하면 된다. HashMap은 내부적으로 거대한 배열을 하나 가지고 있는데 이 배열의 각 칸(인덱스) 하나하나가 바로 버킷이다. 이 버킷 안에서 어떤 일이 벌어지는지 특히 해시 충돌이 발생했을 때 자바가 어떻게 처리하는지 아는 것이 중요하다.
해시 버킷(Hash Bucket)의 기본구조
map.put(“key”, “value”)를 호출하면 다음과 같은 일이 일어난다.
- 해시 계산: 키(“key”)의 해시코드를 구한다.
- 주소 배정: 그 숫자를 배열의 크기로 나눈 나머지를 구해 몇 번째 버킷에 넣을지 정한다. (예: 3번 버킷)
- 저장: 3번째 버킷에 가서 데이터를 넣는다. 이때 3번 버킷이 비어있다면 문제 없지만 이미 데이터가 존재하는 경우 충돌이 발생한다.
해시 충돌
서로 다른 키인데 계산된 해시 값이 같아 주소가 같을 수 있다. 이를 해시 충돌이라고 한다. 이 때 버킷은 단순한 변수에서 자료구조로 변신한다.
자바(HashMap)에서는 Seperate Chaining 방식을 사용하는데 버킷 내부 구조는 데이터 양에 따라 두 가지로 나뉜다.
LinkedList (데이터가 적을 때)
한 버킷에 데이터가 겹치면 LinkedList로 엮어서 저장한다.
- 구조: A -> B -> C
- 조회 속도: O(n) (최악의 경우 리스트 끝까지 다 뒤져야함)
- 사용 시점: 버킷 하나에 데이터가 8개 미만일 때
Red-Black 트리 (데이터가 많을 때)
자바 8에서 도입된 성능 최적화로 개선된 방식이다. 한 버킷에 데이터가 너무 많이 쌓이면(8개 이상) 조회 속도가 느려지는 LinkedList를 버리고 트리(Tree)구조로 리모델링 한다.
- 구조: 균형잡힌 이진트리 (정렬된 상태 유지)
- 조회 속도: O(log N) (데이터가 아무리 많아도 훨씬 빠르다)
- 사용 시점: 버킷 하나에 데이터가 8개 이상 쌓일 때 (다시 6개 이하로 줄어들면 리스트로 돌아간다.)
HashMap 클래스에 Threshold 상수값은 다음과 같이 정의 되어 있다.
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;이러한 구조 덕분에 HashMap은 데이터가 아무리 많이 들어와도 꽤 괜찮은 검색 속도를 유지할 수 있다.
LinkedHashMap / LinedkHashSet
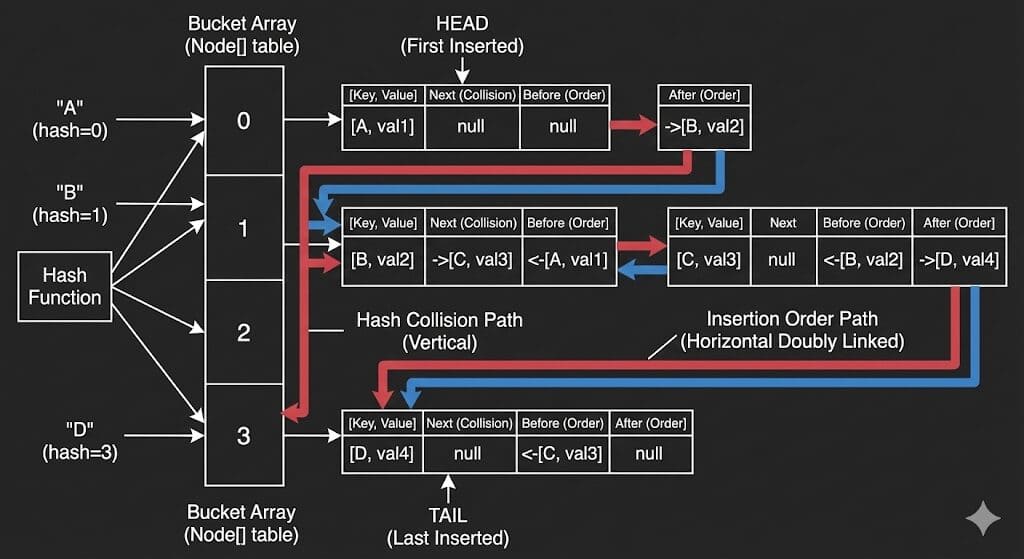
LinkedHashMap과 LinkedHashSet은 기존 HashMap 기능에 이중 연결 리스트를 사용한다는 것이다.
데이터를 저장하는 방식은 해시 테이블(Hash Table)이지만 데이터 끼리의 순서는 link로 묶어서 순서를 기억하도록 하는 구조다.
LinkedHashMap의 노드 구조
일반적인 HashMap의 노드는 4개의 필드를 가진다. 하지만 LinkedHashMap은 순서를 기억하기 위해서 2개의 필드를 더 가진다.
- HashMap Node: Hash, Key, Value, Next
- LinkedHashMap Entry: HashMap Node + Before, After
Before와 After가 바로 ‘나보다 먼저 들어온 놈’, ‘나 다음에 들어온 놈’을 가리키는 링크 역할을 한다.
LinkedHashMap의 내부 구현을 보면 다음과 같이 정의되어 있다.
Node의 Next는 동일 버킷에서 여러 노드가 있을 때(LinkedList 혹은 RB Tree) 해당 버킷 내에서의 링크를 의미하고 Before, After는 버킷과 상관없이 이전과 이후에 입력된 노드를 가르킨다.
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}LinkedHashMap은 다음 두 가지 방식을 사용한다.
- 검색 (Hash Table) – HashMap과 동일
- Key의 해시 값을 계산해서 버킷(배열)의 위치를 찾는다.
- 버킷의 위치를 바로 찾으므로 O(1)의 성능을 갖는다. (버킷 충돌이 발생한 경우는 O(log n))
- HashMap과 마찬가지로 충돌이 나면 Next로 연결되거나 Red-Black Tree가 된다.
- 순서 보장 (Doubly Linked List)
- 모든 데이터(노드)들이 입력된 순서대로 Head 부터 Tail까지 하나의 긴 줄로 연결되어 있다.
- 전체를 순회(Iteration)할 때는 이 길을 따라감으로써 입력 순서를 보장한다.
LinkedHashSet
HashSet이 HashMap의 껍데기였던 것처럼 LinkedHashSet은 LinkedHashMap의 껍데기 역할을 한다.
- 내부적으로 LinkedHashMap을 생성해서 사용한다.
- 데이터는 Key에 저장하고 Value는 더미 객체(PRESENT)를 넣는 방식이 완전히 동일하다.
- 구조적으로 LinkedHashMap과 동일하다.
- 입력 순서를 유지하고 중복을 방지하고자 하는 경우 사용한다.
TreeMap / TreeSet
TreeMap과 TreeSet은 이름에서 알 수 있듯이 내부적으로 처음부터 끝까지 Red-Black Tree로만 이루어져 있다. TreeMap은 버킷이나 해시 함수 같은건 아예 없고 모든 데이터가 하나의 거대한 Red-Black Tree로 저장된다.
TreeMap은 키를 기준으로 비교 연산자를 통해서 정렬되어 저장된다.
내부구조
TreeMap의 내부는 배열 없이 루트 노드 하나에서 시작해서 모든 데이터가 가지치기하듯 연결된 구조다.
- 저장 방식: 데이터를 넣을 때마다 정렬 기준(크기)에 맞춰서 왼쪽(작은값)이나 오른쪽(큰값) 자식으로 찾아 간다.
- 균형 유지: 데이터가 들어오면 즉시 색깔을 칠하고 회전(Rotation)해서 트리의 높이를 logN으로 맞춘다.
- TreeSet: 역시 HashSet과 같이 껍데기일 뿐이고 내부는 TreeMap을 사용한다.
핵심 차이: 해시 vs 비교
TreeMap은 hashCode()와 equals()를 전혀 사용하지 않는다.
| 구분 | HashMap / HashSet | TreeMap / TreeSet |
| 식별 도구 | hashCode(), equals() | compareTo() (또는 Comparator) |
| 저장 위치 | 해시 값으로 계산된 버킷 주소 | 크기 비교를 통해 결정된 트리 위치 |
| 정렬 | 불가능 (뒤죽박죽) | 자동 정렬(오름차순 기본) |
| Null Key | 1개 허용 | 불가 (비교해야 하는데 null이면 에러) |
TreeMap에 객체를 넣으려면 그 객체는 반드시 Comparable 인터페이스를 구현하고 있어야 한다.
(아니면 생성자에 별도의 Comparator를 넣어줘야 한다)
그렇지 않으면 정렬 방법을 알 수 없어 에러(ClassCastException)가 발생한다.
TreeMap은 언제 사용하나?
단순히 데이터 저장이 목적이라면 무조건 HashMap이 낫다. 하지만 순서나 범위가 필요할 때는 TreeMap이 압도적이다.
- 정렬된 데이터가 필요할 때
- 데이터를 넣기만 하면 알아서 가나다순(혹은 지정한 순서)으로 정렬된다. Collections.sort()를 호출할 필요가 없다.
- 범위 검색(Range Search)
- “20대 회원만 가져와”, “이름이 ‘김’으로 시작하는 사람만 찾아줘” 같은 쿼리에 최적화 되어 있다.
- 메서드: subMap(), headMap(), tailMap()
- 가까운 값 찾기
- 정확히 100은 없는데 100이랑 가장 가까운 큰 수는 뭔가?
- 메서드: ceilingEntry() (크거나 같은), floorEntry() (작거나 같은), higherEntry(), lowerEntry()
샘플 코드
다음은 TreeMap을 사용하는 샘플 코드다. 정렬, 범위 추출등과 같은 작업을 손쉽게 할 수 있다.
@Test
void treeMapTest() {
// 1. TreeMap 생성 (기본은 Key 기준 오름차순 정렬)
// 역순(큰 점수가 먼저)으로 하려면 new TreeMap<>(Collections.reverseOrder()) 사용
TreeMap<Integer, String> ranking = new TreeMap<>();
// 2. 데이터 무작위 입력 (넣는 순서는 상관없음, 알아서 정렬됨)
ranking.put(50, "훈이");
ranking.put(95, "철수");
ranking.put(10, "맹구");
ranking.put(88, "영희");
ranking.put(72, "짱구");
System.out.println("=== 1. 전체 랭킹 (자동 정렬됨) ===");
// HashMap이었다면 뒤죽박죽 나왔겠지만, 여긴 점수순으로 나옴
ranking.forEach((score, name) ->
System.out.println(score + "점: " + name)
);
System.out.println("\n=== 2. 특정 점수 구간 검색 (subMap) ===");
// subMap(시작점, 포함여부, 끝점, 포함여부)
// 70점 이상 ~ 90점 미만인 유저만 쏙 뽑아냄
NavigableMap<Integer, String> silverTier = ranking.subMap(70, true, 90, false);
System.out.println("실버 티어(70~89점): " + silverTier);
System.out.println("\n=== 3. 근접값 찾기 (가장 강력한 기능!) ===");
int myScore = 80;
// floorEntry: 80점과 같거나, 없으면 바로 아래 점수 (내림)
Map.Entry<Integer, String> lower = ranking.floorEntry(myScore);
// ceilingEntry: 80점과 같거나, 없으면 바로 위 점수 (올림)
Map.Entry<Integer, String> higher = ranking.ceilingEntry(myScore);
System.out.println("내 점수(" + myScore + ") 바로 아래 라이벌: " + lower.getKey() + "점 (" + lower.getValue() + ")");
System.out.println("내 점수(" + myScore + ") 바로 위 라이벌: " + higher.getKey() + "점 (" + higher.getValue() + ")");
System.out.println("\n=== 4. 1등과 꼴찌 구하기 ===");
System.out.println("1등(최고점): " + ranking.lastEntry()); // Key가 가장 큰 놈
System.out.println("꼴찌(최저점): " + ranking.firstEntry()); // Key가 가장 작은 놈
}실행결과
=== 1. 전체 랭킹 (자동 정렬됨) ===
10점: 맹구
50점: 훈이
72점: 짱구
88점: 영희
95점: 철수
=== 2. 특정 점수 구간 검색 (subMap) ===
실버 티어(70~89점): {72=짱구, 88=영희}
=== 3. 근접값 찾기 (가장 강력한 기능!) ===
내 점수(80) 바로 아래 라이벌: 72점 (짱구)
내 점수(80) 바로 위 라이벌: 88점 (영희)
=== 4. 1등과 꼴찌 구하기 ===
1등(최고점): 95=철수
꼴찌(최저점): 10=맹구Key 타입이 Integer 타입인데 Integer는 Comparable<Integer>를 구현하고 있다.
Set/Map 구현체 비교 및 성능 (Big-O) – Java8 이상 기준
| 구현체 | 기반자료구조 | 조회 | 추가 | 삭제 | 특징 |
| HashSet/ HashMap | Hash Table (+RB Tree) | O(1) ~ O(log n) | O(1) ~ O(log n) | O(1) ~ O(log n) | 순서보장 X 가장 빠름 |
| LinkedHashSet/ LinkedHashMap | HashTable + LinkedList | O(1) ~ O(log n) | O(1) ~ O(log n) | O(1) ~ O(log n) | 입력순서(Insert Order) 보장 |
| TreeSet/ TreeMap | Red-Black Tree | O(log n) | O(log n) | O(log n) | 키 기준 정렬 상태 유지 |
Java 21 Sequenced Collections (시퀀스 컬렉션)
Java 21 (JEP 431)에서는 컬렉션 프레임워크에 가장 큰 구조적 변화가 일어났다. 바로 Sequenced Collections의 도입이다.
순서는 있는데 공통 인터페이스가 없다
이전까지 자바에는 순서가 있는 컬렉션을 아우르는 상위 타입이 없었다.
- List: 순서 있음 (인덱스 접근 가능)
- Deque: 순서 있음 (양끝 접근 가능)
- LinkedHashSet: 순서 있음 (입력 순서)
하지만 이들의 공통 조상인 Collection이나 Set 인터페이스는 순서에 대한 개념이 없다. 그래서 ‘첫 번째 요소’를 가져오는 단순한 작업 조차 구현체마다 제각각이었다.
- List: list.get(0)
- Deque: deque.getFirst()
- LinkedHashSet: iterator().next()
새로운 인터페이스 주입
Java 21은 계층 구조 사이에 3개의 새로운 인터페이스를 추가했다.
- SequencedCollection: Collection을 상속 받으며 List와 Deque의 상위가 된다. addFirst, addLast, getFirst, getLast, removeFirst, removeLast, reversed() 메서드를 제공한다.
- SequencedSet: Set 이면서 순서가 있는 LinkedHashSet, TreeSet 등의 상위 인터페이스다.
- SequencedMap: LinkedHashMap, TreeMap 등의 상위 인터페이스로 firstEntry, lastEntry, pollFirstEntry, pollLastEntry 등을 제공한다.
코드 리팩토링
가장 강력한 기능은 reversed() 뷰이다. 이제 List나 Set을 역순으로 순회하는 것이 너무나 직관적으로 변했다.
다음은 LinkedHashSet의 마지막 요소 가져오기 및 역순 조회 코드가 어떻게 개선되었는지를 나타낸다.
Java 21 이전
LinkedHashSet<String> set = new LinkedHashSet<>();
set.add("Apple");
set.add("Banana");
set.add("Cherry");
// 마지막 요소를 가져오기 위해 전체를 순회하거나 배열로 변환해야 했음
String lastElement = null;
for(String s : set) lastElement = s; // O(n)
// 역순 출력을 위해 별도 리스트 생성 필요 (메모리 낭비)
List<String> list = new ArrayList<>(set);
Collections.reverse(list);
for(String s : list) {
System.out.println(s);
}Java 21 이후
// 마지막 요소 즉시 접근 O(1)
String lastElement = set.getLast();
// 역순 뷰를 통한 순회 (메모리 복사 없음)
for(String s : set.reversed()) {
System.out.println(s);
}여기서 reversed()는 새로운 컬렉션을 복사해서 만드는 것이 아니라 원본 컬렉션을 거꾸로 보여주는 뷰(view)를 반환한다. 따라서 메모리 효율이 뛰어나며 reversed() 뷰에서 요소를 삭제하면 원본에서도 삭제된다.
https://stackoverflow.com/questions/79603303/how-can-i-process-elements-in-reverse-order-across-different-collection-types
https://nipafx.dev/inside-java-newscast-45/
불변성과 스트림
Java 9이후 그리고 Java 16을 거치면서 컬렉션을 생성하고 변환하는 방식이 간결하고 안전해졌다.
List.of vs Arrays.asList: 불변성의 차이
리스트를 초기화할 때 이 두가지를 주로 혼용하는 경우들이 많이 있는데 이 둘은 결정적인 차이가 있다.
| 특성 | Arrays.asList(1, 2, 3) | List.of(1, 2, 3) |
| 변경 가능성 | 고정 크기(Fixed-size) set()으로 값 변경은 가능하지만 add/remove는 불가 | 완전 불변(Immutable). 값 변경, 추가, 삭제 모든 시도시 UnsupportedOperationException 발생 |
| null 허용 | 허용함. | 허용 안 함. 포함시 NullPointerException 발생 |
| 참조 관계 | 원본 배열의 뷰(view)역할. 원본 배열이 바뀌면 리스트도 바뀜 | 값 자체를 복사하여 독립적인 리스트 생성 |
권장 사항: 데이터 전송 객체(DTO)나 설정값처럼 변경되지 않아야 할 목록을 만들 때는 항상 List.of를 사용하여 의도치 않은 변경사항을 방지하는 것이 좋다.
Stream API: Stream.toList() vs Collectors.toList()
Java 8에서 스트림 결과를 리스트로 모을 때 collect(Collector.toList())를 사용했다. Java 16부터는 Stream.toList()가 도입되었다.
// Java 8 스타일
List<String> list1 = stream.collect(Collectors.toList());
// Java 16 스타일
List<String> list2 = stream.toList();차이점은 다음과 같다.
- Collectors.toList(): 반환되는 리스트가 ArrayList등 변경 가능한 리스트일 가능성이 높다. (명세상 보장되지 않음)
- Stream.toList(): 변경 불가능한(Unmodifiable) 리스트를 반환한다. 메모리 사용량이 최적화되어 있고 null 값을 허용하지 않는다.
결과 리스트를 수정할 일이 없다면 더 간결하고 안전한 Stream.toList()를 사용할 것을 권장한다.
소소한 팁
contains() 함정
ArrayList.contains()를 사용하여 중복 체크를 하는 경우가 많다.
List<String> list = new ArrayList<>();
//... 데이터 10만 개 추가...
if (!list.contains("Target")) { // 여기서 O(n) 발생!
list.add("Target");
}ArrayList의 contains는 리스트 전체를 순회한다. 데이터가 많아질수록 성능은 선형적으로 나빠진다 (O(n)). 존재 여부 확인이 빈번하다면 HashSet을 사용하는 것을 추천한다. HashSet의 contains 성능은 O(1)이다. 같은 contains 메서드라고 하더라도 내부 자료 구조에 따라 성능 차이 발생한다는 것을 알 수 있다.
안전한 삭제
루프를 돌면서 리스트의 요소를 삭제하는 코드는 개발자가 많이 실수하는 부분이다. for-each 루프에서 list.remove()를 호출하면 ConcurrentModificationException이 발생한다.
for (String s : list) {
if (s.startsWith("A")) {
list.remove(s); // ConcurrentModificationException 예외 발생!
}
}iterator가 리스트를 순회하는 도중에 리스트의 내용이(구조) 변경되었기 때문에 예외가 발생한다. (for-each는 iterator동작)
java 8이전의 경우에는 iterator의 remove()를 호출하여 삭제해야 한다.
Iterator<String> iter = list.iterator();
while (iter.hasNext()) {
String s = iter.next();
if (s.startsWith("A")) {
iter.remove(); // 안전함: Iterator가 삭제하고 스스로 상태 업데이트함
}
}java 8부터는 내부적으로 최적화된 removeIf 메서드를 제공한다.
list.removeIf(s -> s.startsWith("A"));removeIf는 내부적으로 iterator를 사용하여 안전하게 삭제하고 ArrayList의 경우 삭제 후 배열 복사 횟수를 최소화 하도록 최적화 되어 있어 성능적으로도 유리하다.
지금까지 Java Collection Frameworkd에서 뿌리라고 할 수 있는 List, Map, Set에 대해서 정리해보았다. Collection은 단순히 데이터 저장소를 넘어 그 특성에 맞게 내부 자료 구조가 어떻게 되어 있고 동작하는지 이해하는 것이 중요한 것 같다. 근데 매번 볼 때마다 새로운 느낌은 왜일까? ㅠㅠ 볼 때는 이해가 되는데 지나고나면 금방 잊어버린다. 자주 들여다봐야겠다.
참고하면 좋은 요약
- 일반적인 상황에서는 ArrayList가 LinkedList 보다 빠르다. (CPU Cache locality)
- 중복 제거와 빠른 검색이 필요할 땐 주저없이 HashSet을 사용하자.
- Java 21을 사용한다면 SequencedCollection의 reversed(), getLast()등을 적극 활용하자.
- 불변 리스트가 필요할 땐 List.of()와 Stream.toList()를 사용하자.