
자바 애플리케이션의 성능을 결정짓는 핵심은 효율적인 메모리 설계와 이를 뒷받침하는 검증 과정에 있다. 이번 포스팅에서는 문자열 최적화부터 가상스레드까지 메모리를 아끼는 자바 메모리 최적화 기법을 소개하고자 한다.
공통으로 사용되는 테스트 코드
메모리 최적화 기법을 검증하기 위한 테스트 코드에서 공통으로 사용하기 위해 정의한 클래스는 다음과 같다.
public class UsedMemory {
public static long getUsedMemory() {
return Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory();
}
}최적화기법1: 가변 문자열 처리를 통한 힙 오버헤드 감소
자바의 String 객체는 불변이라는 특성을 가진다. 이는 멀티스레드 환경에서의 안전성과 문자열 풀(String Pool)을 통한 리터럴 공유를 가능하게 하지만 빈번한 수정이 발생하는 연산에서는 치명적인 메모리 비효율을 초래한다.
String에 대한 ‘+’ 연산은 논리적으로는 기존 문자열에 내용을 추가하는 것이지만, 실제 메모리 상에서는 두 문자열의 내용을 합친 완전히 새로운 String 객체와 내부 byte 배열을 힙에 생성한다. 반복문 내에서 이러한 연산이 수행될 경우 최종 결과물을 만들기 위해 수많은 중간 단계의 String 객체들이 생성되었다가 즉시 Gabage로 전락한다. 이는 Eden 영역을 빠르게 소진시키고 Minor GC(Young Generation GC)의 빈도를 높여 전체 애플리케이션의 성능을 저하시키게 된다.
테스트 코드를 통한 성능 비교
public class StringOptimizationTest {
private static final int LOOP_COUNT = 50_000;
private static final String APPEND_DATA = "JavaMemoryOpt";
@Test
void string_concatenation_test() {
StopWatch stopWatch = new StopWatch();
String result = "";
long startMemory = UsedMemory.getUsedMemory();
stopWatch.start();
for ( int i = 0; i < LOOP_COUNT; i++ ) {
result += APPEND_DATA;
}
stopWatch.stop();
long duration = stopWatch.getTotalTimeMillis();
long endMemory = UsedMemory.getUsedMemory();
System.out.println("\n");
System.out.println("Time: " + duration + " ms");
System.out.println("Result Length: " + result.length() + " bytes");
System.out.println("Memory Allocation Data: " + (endMemory - startMemory) + " bytes");
}
@Test
void string_builder_test() {
StopWatch stopWatch = new StopWatch();
StringBuilder sb = new StringBuilder();
long startMemory = UsedMemory.getUsedMemory();
stopWatch.start();
for ( int i = 0; i < LOOP_COUNT; i++ ) {
sb.append(APPEND_DATA);
}
stopWatch.stop();
String result = sb.toString();
long duration = stopWatch.getTotalTimeMillis();
long endMemory = UsedMemory.getUsedMemory();
System.out.println("\n");
System.out.println("Time: " + duration + " ms");
System.out.println("Result Length: " + result.length() + " bytes");
System.out.println("Memory Allocation Data: " + (endMemory - startMemory) + " bytes");
}
}위 테스트 코드를 실행한 결과는 다음과 같다.
string_concatenation_test
Time: 932 ms
Result Length: 650000 bytes
Memory Allocation Data: 14325472 bytes
-------------------------------------------
string_builder_test
Time: 1 ms
Result Length: 650000 bytes
Memory Allocation Data: 4692232 bytes속도 메모리 사용량에 있어서 상당히 많은 차이가 있음을 알 수 있다. 힙 사용량에 대한 그래프를 살펴보자.
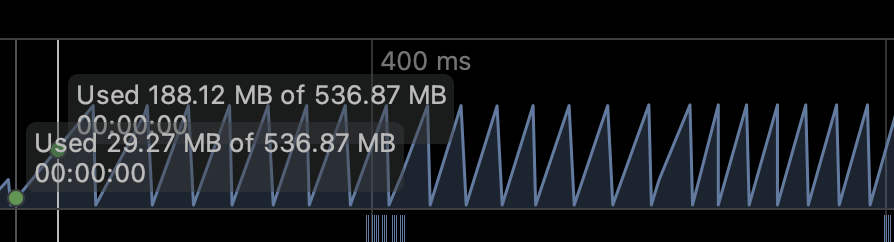

string_concatenation_test의 힙 그래프가 톱니바퀴 모양으로 요동치는 것은 String 객체가 빠르게 생성되고 Minor GC에 의해서 정리되는 전형적인 패턴이다. 반면 string_builder_test는 처음 메모리가 살짝 올라갔다가 바로 정리되는 모습을 볼 수가 있고 GC가 거의 발생하지 않음을 알 수 있다.
문자열에 대한 ‘+’ 연산 대신에 StringBuilder, StringBuffer를 사용하자!!
일반적으로 StringBuilder를 사용하지만 멀티스레드 환경에서 StringBuilder를 공유해서 사용해야 하는 경우에는 스레드 안전한 StringBuffer를 사용해야 한다.
최적화기법2: 동적 컬렉션의 재할당 비용 최소화
ArrayList와 같은 동적 배열 기반의 컬렉션은 가장 빈번하게 사용하는 자료구조다. 하지만 ArrayList의 내부 동작을 모르고 사용하면 메모리 할당과 GC 압력 측면에서도 상당한 비용을 지불해야 할 수 있다.
ArrayList는 기본 생성자를 통해 인스턴스를 생성하면 기본 10개의 capacity를 가지고 생성된다. 데이터가 추가되어 capacity가 다 찰 때마다 기존 용량의 약 1.5배에 해당하는 새로운 배열을 힙에 할당하고 기존 데이터를 새로운 힙에 복사한다. 예를 들어 100만개의 데이터를 추가한다고 가정하면 10에서 시작하여 15, 22, 33… 순으로 수차례 재할당이 발생한다. 이 과정에서 이전 단계의 배열들은 모두 가비지가 되며 복사 연산 자체가 메모리 대역폭을 소모한다. 마지막 재할당 시점에는 실제 필요한 데이터보다 더 큰 공간이 할당되어(ex. 100만개가 필요한데 150만개 크기의 배열이 할당됨) 메모리 낭비가 발생할 수 있다.
테스트 코드를 통한 메모리 동작 비교
다음은 초기 capacity 설정이 성능과 메모리에 미치는 영향을 비교하는 코드다.
public class ArrayListSizingTest {
private static final int ELEMENT_COUNT = 5_000_000;
@Test
void use_default_capacity_test() {
StopWatch stopWatch = new StopWatch();
long startMemory = UsedMemory.getUsedMemory();
stopWatch.start();
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < ELEMENT_COUNT; i++) {
list.add( i );
}
stopWatch.stop();
long duration = stopWatch.getTotalTimeMillis();
long endMemory = UsedMemory.getUsedMemory();
System.out.println("\n");
System.out.println("Time: " + duration + " ms");
System.out.println("Result Length: " + list.size());
System.out.println("Memory Allocation Data: " + (endMemory - startMemory) + " bytes");
}
@Test
void test_presize_capacity_test() {
StopWatch stopWatch = new StopWatch();
long startMemory = UsedMemory.getUsedMemory();
stopWatch.start();
ArrayList<Integer> list = new ArrayList<>(ELEMENT_COUNT);
for (int i = 0; i < ELEMENT_COUNT; i++) {
list.add( i );
}
stopWatch.stop();
long duration = stopWatch.getTotalTimeMillis();
long endMemory = UsedMemory.getUsedMemory();
System.out.println("\n");
System.out.println("Time: " + duration + " ms");
System.out.println("Result Length: " + list.size());
System.out.println("Memory Allocation Data: " + (endMemory - startMemory) + " bytes");
}
}결과
use_default_capacity_test
Time: 59 ms
Result Length: 5000000
Memory Allocation Data: 157113704 bytes
----------------------------------------
test_presize_capacity_test
Time: 49 ms
Result Length: 5000000
Memory Allocation Data: 104841504 bytesmemory allocation 상황은 다음과 같다.
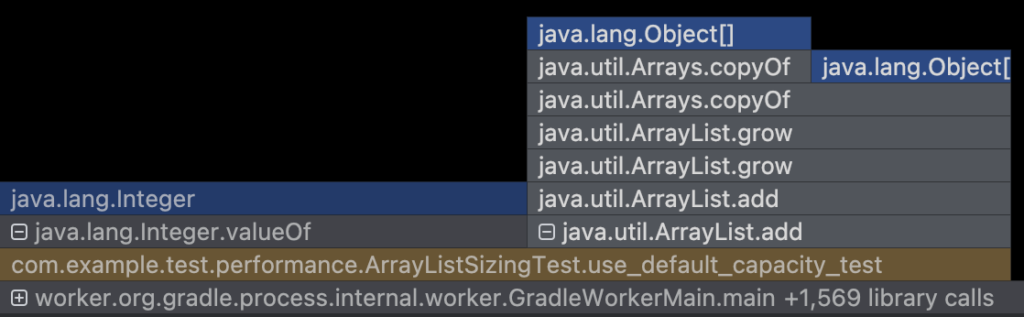

use_default_capacity_test의 경우 grow 호출(capacity가 full차서 재할당 호출)이 발생하면서 copyOf가 발생하는 것을 알 수 있다.
반면에 test_presize_capacity_test의 경우 grow 호출은 없고 한번 메모리를 할당하는 것을 확인할 수 있다.
내부적으로 동적할당이 발생하는 컬렉션을 사용하는 경우 크기를 예측 가능하다면 capacity를 미리 지정해 주자.
최적화기법3: 객체 풀링을 통한 고비용 자원 관리
자바의 GC 성능이 발전하면서 모든 객체를 풀링할 필요는 없다. 그러나 생성 비용이 높거나 OS 리소스와 연결된 객체 (ex. Connection, Thread, Large Buffer)에 대해서는 풀링이 여전히 필수적인 최적화 기법이다.
일반적인 객체 할당은 힙의 Eden 영역 포인터만 증가시키면 되므로 매우 빠르다. 하지만 DB 연결과 같은 자원은 네트워크 핸드쉐이크, 인증, 소켓할당등 OS 레벨의 무거운 작업을 수행한다. 이러한 객체를 요청마다 생성하고 파괴하는 것은 시스템 전체의 처리량을 급격히 떨어뜨리며, 잦은 소멸은 GC에게 불필요한 부하를 준다. 객체 풀링은 이러한 객체를 미리 생성해두고 재사용함으로써 초기 생성 이후 할당 비용을 0에 가깝게 만들고 GC 대상에서 제외시켜 메모리 안정성을 확보하는 것이 좋다.
테스트 코드를 통한 메모리 동작 비교
public class PoolingTest {
// 생성 비용이 비싸다고 가정해보자..
class HeavyResource {
private byte[] buffer;
// 생성시 100KB 할당 및 CPU 지연 발생
public HeavyResource() {
buffer = new byte[1024 * 100];
try {
Thread.sleep( 5 );
}
catch ( InterruptedException e ) {
throw new RuntimeException( e );
}
}
public void execute() {
//리소스 사용 로직
int length = buffer.length;
}
}
class SimpleObjectPool {
private BlockingQueue<HeavyResource> pool;
public SimpleObjectPool(int size) {
pool = new ArrayBlockingQueue<>( size );
for ( int i = 0; i < size; i++ ) {
pool.offer( new HeavyResource() );
}
}
public HeavyResource take() {
try {
// pool에서 하나를 꺼냄. 없으면 대기.
return pool.take();
}
catch ( InterruptedException e ) {
throw new RuntimeException( e );
}
}
public void retrieve( HeavyResource heavyResource ) {
// 사용 후 pool에 반납
pool.offer( heavyResource );
}
}
private static final int ITERATION_COUNT = 1000;
@Test
void normal_allocation_test() {
StopWatch stopWatch = new StopWatch();
long startMemory = UsedMemory.getUsedMemory();
stopWatch.start();
for ( int i = 0; i < ITERATION_COUNT; i++ ) {
HeavyResource heavyResource = new HeavyResource();
heavyResource.execute();
}
stopWatch.stop();
long duration = stopWatch.getTotalTimeMillis();
long endMemory = UsedMemory.getUsedMemory();
System.out.println("[Allocation Mode]");
System.out.println("Time: " + duration + " ms");
System.out.println("Memory Allocation Data: " + (endMemory - startMemory) + " bytes");
}
@Test
void pooling_test() {
StopWatch stopWatch = new StopWatch();
long startMemory = UsedMemory.getUsedMemory();
stopWatch.start();
// 10개 짜리 resource pool 생성
SimpleObjectPool pool = new SimpleObjectPool( 10 );
for ( int i = 0; i < ITERATION_COUNT; i++ ) {
HeavyResource resource = pool.take();
if ( resource != null ) {
resource.execute();
pool.retrieve( resource );
}
}
stopWatch.stop();
long duration = stopWatch.getTotalTimeMillis();
long endMemory = UsedMemory.getUsedMemory();
System.out.println("[Pooling Mode]");
System.out.println("Time: " + duration + " ms");
System.out.println("Memory Allocation Data: " + (endMemory - startMemory) + " bytes");
}
}HeavyResource는 무거운 동작을 하는 리소스 클래스라고 가정한다.
normal_allocation-test는 1000개의 HeavyResource를 생성하여 실행한다.
pooling_test는 10개의 HeavyResource를 pool에 담아놓고 재사용하여 실행한다.
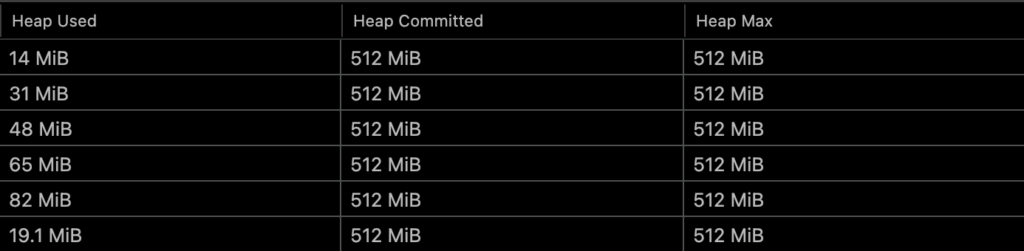
pooling_test는 GC Heap 동작에 GC가 발생하지 않았다.
무거운 객체를 사용해야 하는 경우에는 pooling을 사용하자.
최적화기법4: 약한 참조(WeakReference)를 이용한 객체 생명주기 기반 메모리 관리
HashMap과 같은 강한 참조 기반의 컨테이너에 객체를 넣어두고 애플리케이션의 다른 곳에서 해당 객체를 더 이상 사용하지 않더라도 맵이 참조를 유지하고 있어 GC가 수거할 수 없다. WeakHashMap은 이러한 문제를 해결하기 위해 Key에 대해 약한 참조를 사용한다. 이는 GC가 발생했을 때 해당 키 객체를 참조하는 곳에 WeakHashMap 뿐이라면 GC 시점에 수거하도록 허용한다.
테스트 코드를 통한 동작 비교
public class WeakHashMapTest {
// 식별 가능한 키 객체
static class UserKey {
private String id;
public UserKey(String id) {
this.id = id;
}
@Override
public String toString() {
return "UserKey{" + id + "}";
}
// 객체가 GC 될 때 호출됨 (디버깅 용도)
@Override
protected void finalize() throws Throwable {
System.out.println(this + " is being finalized (Collected by GC)");
}
}
@Test
void hashmap_test() throws InterruptedException {
System.out.println("=== HashMap Test (Potential Leak) ===");
Map<UserKey, String> map = new HashMap<>();
UserKey key = new UserKey("StrongRef");
map.put(key, "SessionData");
System.out.println("Map contains: " + map);
// 외부 참조 제거 (그러나 Map 내부에는 Key가 강하게 참조됨)
key = null;
System.out.println("Requesting GC...");
System.gc();
Thread.sleep(1000); // GC 수행 대기
// 결과: finalize 호출되지 않음, Map에 여전히 데이터 존재
System.out.println("After GC, Map contains: " + map);
}
@Test
void weakhashmap_test() throws InterruptedException {
System.out.println("=== WeakHashMap Test (Auto Clean) ===");
Map<UserKey, String> map = new WeakHashMap<>();
UserKey key = new UserKey("WeakRef");
map.put(key, "SessionData");
System.out.println("Map contains: " + map);
// 외부 참조 제거 (이제 Key는 Weakly Reachable 상태)
key = null;
System.out.println("Requesting GC...");
System.gc();
Thread.sleep(1000);
// 결과: finalize 호출됨, Map에서 엔트리 자동 제거됨
System.out.println("After GC, Map contains: " + map);
}
}hashmap_test와 weakhashmap_test의 실행 결과는 다음과 같다.
hashmap_test
=== HashMap Test (Potential Leak) ===
Map contains: {UserKey{StrongRef}=SessionData}
Requesting GC...
After GC, Map contains: {UserKey{StrongRef}=SessionData}
---------------------------------------------------------
weakhashmap_test
=== WeakHashMap Test (Auto Clean) ===
Map contains: {UserKey{WeakRef}=SessionData}
Requesting GC...
UserKey{WeakRef} is being finalized (Collected by GC)
After GC, Map contains: {}HashMap과 WeakHashMap에 UserKey 인스턴스를 키로 하여 각각 저장 후 UserKey 인스턴스를 null로 변경 후 GC를 강제로 수행 후 결과를 살펴보면 차이가 확연히 드러난다.
HashMap은 강한 참조로 인해서 UserKey 인스턴스가 null로 변경 됨에도 HashMap에 있는 UserKey 인스턴스는 그대로 살아있어 GC 대상이 되지 않는 것을 알 수 있다.
반면 WeakHashMap은 약한 참조로 인해서 UserKey 인스턴스가 null이 된 후 GC가 발생하는 시점에 메모리가 회수됨을 확인할 수 있다.
최적화기법5: 가상 스레드를 통한 동시성 메모리 혁신
Java21(LTS)에서 정식 도입된 가상 스레드는 자바의 동시성 모델을 근본적으로 변화시켰다. 기존의 플랫폼 스레드는 OS커널 스레드와 1:1로 매핑되며 스레드 하나당 고정된 크기의 네이티브 스택 메모리(일반적으로 1MB 이상)를 점유한다. 이는 수만 개의 동시 접속을 처리해야 하는 대용량 서버에서 힙 메모리가 아닌 네이티브 메모리 고갈을 일으키는 주범이 된다.
전통적인 방식에서는 10_000개의 스레드를 생성하면 약 10GB(10000 * 1MB)의 네이티브 메모리가 예약된다. 이는 실제 스레드가 수행하는 작업의 경중과 상관없이 발생하는 고정 비용이다. 우리가 기존의 플랫폼 스레드를 무한정 사용할 수 없는 이유이고 스레드 풀을 사용하는 이유다. 반면 가상 스레드는 JVM내부의 힙 메모리에 존재하는 자바 객체(task)일 뿐이며 OS 스레드에 1:N으로 매핑된다. 가상 스레드의 스택 정보는 힙에 저장되며 필요에 따라 동적으로 크기가 조절되므로 스레드 하나당 수백 바이트에서 수 KB정도의 메모리만 차지한다.
Java21 이상 버전을 사용한다면 IO 작업에 대해서는 가상 스레드 도입을 적극적으로 검토하자.
처리량이 대폭 증가함에 따라 IO 처리와 관련된 몇 가지 이슈가 발생할 수는 있지만, 그럼에도 불구하고 가상 스레드는 충분히 도입할 가치가 있다. 물론 가상 스레드 환경에서는 기존의 ThreadLocal 사용을 ScopedValue로 대체해야 하는 등 몇 가지 설계상 고려사항이 필요하다. 그러나 이러한 변경 비용을 감안하더라도, 확장성과 처리량 측면에서 얻는 이점은 매우 크다.
Virtual Thread와 Scoped Value에 대해서는 아래 포스팅을 참고하기 바란다.
java21 처리량 향상을 위한 대안 – virtual thread
ThreadLocal의 개선: Java Scoped Value 가이드