
이번 포스팅에서는 Java Virtual Threads를 프로덕션 환경에 적용하기 위한 실전 패턴에 대해서 정리하고자 한다. Virtual Threads는 JDK 21에서 정식 출시되었지만, 솔직히 그때는 프로덕션에 넣기엔 찜찜한 구석이 있었다. synchronized 블록에서 pinning이 발생하고, ThreadLocal이 메모리를 잡아먹는 문제가 남아 있었기 때문이다. JDK 24에서 pinning이 해결되고, JDK 25 LTS에서 ScopedValue가 정식 API가 되면서 상황이 달라졌다. 이 글에서는 내부 동작 원리부터 Spring Boot 적용, 벤치마크 수치, 그리고 실전에서 주의해야 할 내용까지 코드와 함께 다룬다.
Java Virtual Threads의 속을 들여다보면 — Mount와 Unmount
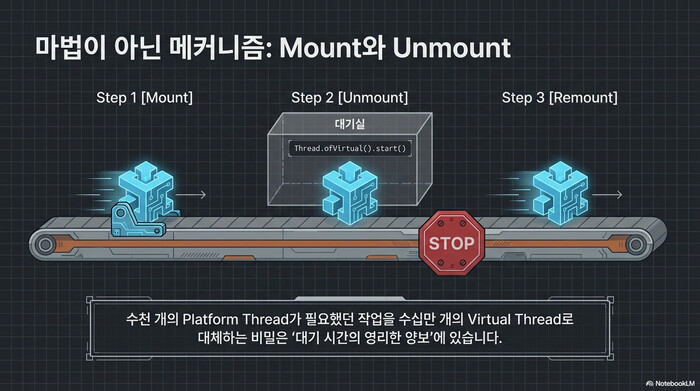
Java Virtual Threads를 한 문장으로 요약하면, carrier thread 위에 올라탔다(mount) 내렸다(unmount) 하는 경량 스레드이다. 기존 platform thread는 OS 스레드와 1:1로 매핑된다. 하나의 스레드가 블로킹 I/O를 만나면 OS 스레드째 대기 상태에 빠지고, 그 동안 다른 작업은 처리할 수 없다. Virtual Thread는 다르다. 블로킹 지점에서 carrier thread로부터 스스로 내려오고, 다른 Virtual Thread가 같은 carrier thread를 바로 재활용한다.
Platform Thread: Java의 전통적인 스레드. OS 스레드와 1:1로 대응한다.
Carrier Thread는 Virtual Thread를 실제로 실행해주는 Platform Thread를 일컫는다.
이 구조 덕분에 수천 개의 platform thread가 필요했던 작업을 수십만 개의 Virtual Thread로 처리할 수 있다. 그렇다고 “무한히 생성해도 된다”는 뜻은 아니다. Virtual Thread가 unmount되지 못하는 상황(pinning)이 발생하면 carrier thread가 점유되고, 그 순간 Virtual Threads의 이점은 사라진다.
// Virtual Thread 생성 — 가장 기본적인 방법
Thread vt = Thread.ofVirtual()
.name("worker-", 0) // 이름 접두사와 시작 번호 지정
.start(() -> {
// 블로킹 I/O 호출 시 자동으로 carrier thread에서 unmount
String result = callExternalApi("/api/data");
processResult(result);
});Thread.ofVirtual()이 Virtual Thread 빌더를 반환한다. name("worker-", 0)으로 이름 패턴을 지정해두면 디버깅할 때 worker-0, worker-1로 식별할 수 있어 편하다. 중요한 건 callExternalApi() 같은 블로킹 I/O 지점에서 JVM이 알아서 Virtual Thread를 carrier thread에서 분리한다는 점이다. 비동기 콜백을 작성할 필요가 없다.
// 10만 개 Virtual Thread를 동시 실행하는 벤치마크
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
long start = System.nanoTime();
List<Future<Integer>> futures = IntStream.range(0, 100_000)
.mapToObj(i -> executor.submit(() -> {
Thread.sleep(Duration.ofMillis(50)); // I/O 대기 시뮬레이션
return i;
}))
.toList();
// 모든 태스크 완료 대기
for (Future<Integer> f : futures) {
f.get();
}
long elapsed = System.nanoTime() - start;
System.out.printf("완료: %.2f초%n", elapsed / 1_000_000_000.0);
}10만 개의 Virtual Thread를 동시에 띄워서 각각 50ms씩 대기시키는 벤치마크이다. 일반적인 개발 머신에서 수 초 내에 끝난다. 같은 작업을 platform thread로 돌려보면 체감이 확실하다. 메모리 한계에 걸리거나, 실행 시간이 수십 배로 늘어난다. newVirtualThreadPerTaskExecutor()는 submit할 때마다 새 Virtual Thread를 만들고, try-with-resources 블록이 끝나면 알아서 정리된다.
Spring Boot에서 Java Virtual Threads 한 줄로 켜기
Spring Boot 3.2부터 Java Virtual Threads를 공식 지원한다. 설정은 단 한 줄이면 충분하다.
# application.yml — Virtual Threads 활성화
spring:
threads:
virtual:
enabled: true # Tomcat/Jetty가 요청마다 Virtual Thread를 사용이 한 줄이면 내장 Tomcat이나 Jetty가 HTTP 요청마다 platform thread 풀 대신 Virtual Thread를 쓴다. applicationTaskExecutor 빈도 자동으로 바뀌고, RabbitMQ, Kafka, Redis 리스너도 같이 적용된다.
import java.util.List;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@SpringBootApplication
public class VirtualThreadDemoApplication {
public static void main(String[] args) {
SpringApplication.run(VirtualThreadDemoApplication.class, args);
}
}
@RestController
class OrderController {
private final OrderService orderService;
OrderController(OrderService orderService) {
this.orderService = orderService;
}
@GetMapping("/orders")
public List<Order> getOrders() {
// spring.threads.virtual.enabled=true이면
// 이 메서드는 Virtual Thread에서 실행된다
return orderService.findAll(); // JDBC 블로킹 I/O
}
}spring.threads.virtual.enabled=true만 켜두면 /orders 요청이 Virtual Thread에서 처리된다. orderService.findAll()은 JDBC를 통한 블로킹 호출이지만, Virtual Thread가 DB 응답을 기다리는 동안 carrier thread를 양보한다. 덕분에 동시 수천 개 요청을 소화할 수 있고, 컨트롤러 코드는 한 줄도 바꿀 필요가 없다.
벤치마크 수치 — 정말 빨라지는가?

말만으로는 설득이 안 되니 수치를 보자. I/O 바운드 Spring Boot 애플리케이션에서 500명 동시 사용자 부하 테스트 결과이다.
| 항목 | Platform Thread (200 풀) | Virtual Threads | 개선 |
|---|---|---|---|
| 처리량 (req/s) | 약 42 | 약 113 | 2.7배 |
| 99번째 백분위 응답시간 | 8.2초 | 2.0초 | 4배 단축 |
| 메모리 사용량 | 약 3,060MB | 약 1,750MB | 43% 감소 |
| 스레드 수 (동일 처리량) | 200 | 43 | 79% 감소 |
처리량 2.7배, 꼬리 지연시간 4배 단축. 눈에 띄는 건 스레드 수가 200개에서 43개로 줄었다는 점이다. Virtual Thread 자체는 수만 개 생성되지만, 실제로 OS 스레드(carrier thread)를 쓰는 건 그 정도면 충분하다.
다만 한 가지 함정이 있다. CPU 집약적 워크로드(암호화, 압축, 행렬 연산)에서는 수치가 거의 같다. Java Virtual Threads의 이점은 “대기 시간을 공유”하는 데서 나온다. 대기 시간 자체가 없는 CPU 바운드 작업에는 기존 ForkJoinPool이나 parallel stream이 맞다.
Pinning의 악몽, 그리고 JDK 24가 가져온 해방
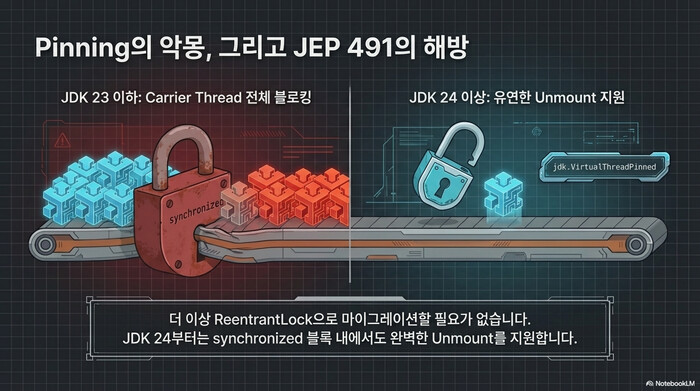
Java Virtual Threads 초기 도입을 망설이게 만든 주범이 pinning이다. synchronized 블록 안에서 블로킹 I/O를 수행하면 Virtual Thread가 carrier thread에서 내려오지 못한다. 그 carrier thread는 꼼짝없이 점유당하고, 다른 Virtual Thread는 실행 기회를 잃는다.
// JDK 23 이하에서 pinning이 발생하는 코드
public class LegacyService {
// synchronized 블록 안에서 블로킹 호출 → pinning 발생!
public synchronized String fetchData() {
return httpClient.send(request, HttpResponse.BodyHandlers.ofString())
.body(); // carrier thread가 점유됨
}
}synchronized 메서드 안에서 HTTP 호출이 발생하면 Virtual Thread는 carrier thread에서 내려올 수 없다. 동시 요청이 몰리면 carrier thread가 모두 점유되고, 그 시점부터 Virtual Threads나 platform threads나 다를 게 없어진다.
JDK 24의 JEP 491 — synchronized에서도 unmount 가능
JEP 491이 이 문제를 끝냈다. JDK 24부터 synchronized 블록 안에서도 Virtual Thread가 carrier thread를 양보할 수 있다. 이전까지는 synchronized를 전부 ReentrantLock으로 바꾸라는 권고가 있었는데, JDK 24 이상이라면 그 수고를 할 필요가 없다.
// JDK 23 이하: ReentrantLock으로 마이그레이션 (pinning 회피)
import java.util.concurrent.locks.ReentrantLock;
public class MigratedService {
private final ReentrantLock lock = new ReentrantLock();
public String fetchData() {
lock.lock(); // ReentrantLock은 pinning을 유발하지 않음
try {
return httpClient.send(request, HttpResponse.BodyHandlers.ofString())
.body();
} finally {
lock.unlock();
}
}
}JDK 23 이하에서 pinning을 피하려면 이렇게 ReentrantLock으로 바꿔야 했다. lock.lock()에서 대기할 때 Virtual Thread는 carrier thread를 양보할 수 있어서 pinning이 발생하지 않는다. JDK 24 이상이라면? 기존 synchronized를 그냥 두면 된다.
Pinning 감지 방법
JDK 23까지는 JVM 옵션 -Djdk.tracePinnedThreads=short로 pinning을 추적했지만, JDK 24부터는 synchronized pinning 자체가 해결되면서 이 옵션이 사라졌다. 그래도 네이티브 코드나 JNI 호출에 의한 pinning은 여전히 존재한다. 이런 경우 Java Flight Recorder(JFR)의 jdk.VirtualThreadPinned 이벤트로 잡아낼 수 있다.
# JFR로 Virtual Thread pinning 이벤트 수집
jcmd <PID> JFR.start name=vt-pinning settings=default duration=60s filename=pinning.jfr
# 수집된 이벤트 확인
jfr print --events jdk.VirtualThreadPinned pinning.jfr60초간 JFR 프로파일링을 돌리고 pinning 이벤트만 뽑아보는 명령이다. 여기서 이벤트가 자주 찍힌다면 해당 코드 경로에 네이티브 호출이 섞여 있을 가능성이 높다.
ThreadLocal은 이제 잊어라 — ScopedValue가 왔다
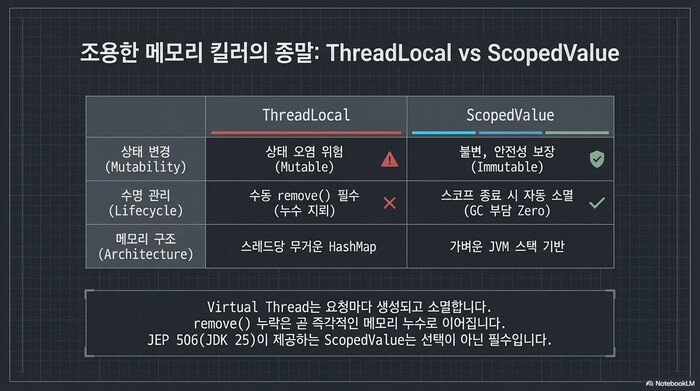
Java Virtual Threads 환경에서 ThreadLocal은 조용한 메모리 킬러이다. Platform thread는 풀에서 재사용되니까 ThreadLocal 값이 오래 살아남아도 문제가 크지 않았다. 하지만 Virtual Thread는 요청마다 새로 생기고 사라진다. ThreadLocal.remove()를 빼먹으면 GC가 치우기 전까지 메모리를 잡아먹는다.
JDK 25에서 정식 API가 된 ScopedValue(JEP 506)가 이 문제를 해결한다. 값이 불변이고, 스코프가 끝나면 알아서 사라진다.
ThreadLocal의 개선: Java Scoped Value 가이드 참고
import java.lang.ScopedValue;
public class RequestContext {
// ScopedValue 선언 — static final로 한 번만 정의
private static final ScopedValue<String> CURRENT_USER = ScopedValue.newInstance();
private static final ScopedValue<String> TRACE_ID = ScopedValue.newInstance();
public void handleRequest(String userId, String traceId) {
// where()로 값 바인딩 → run() 블록 안에서만 유효
ScopedValue.where(CURRENT_USER, userId)
.where(TRACE_ID, traceId)
.run(() -> {
// 이 블록 안의 모든 코드에서 CURRENT_USER.get() 사용 가능
processOrder();
sendNotification();
// run() 블록이 끝나면 바인딩 자동 해제 — remove() 불필요
});
}
private void processOrder() {
String user = CURRENT_USER.get(); // "userId" 반환
String trace = TRACE_ID.get(); // "traceId" 반환
logger.info("[{}] 주문 처리: {}", trace, user);
}
}ScopedValue.where()로 값을 바인딩하면 run() 블록 안에서만 유효하다. 블록이 끝나면 바인딩이 자동으로 풀린다. ThreadLocal의 고질병이었던 remove() 누락 걱정이 없다. 값이 불변이라 자식 Virtual Thread에서도 안전하게 공유되고, JVM이 상수로 최적화할 수도 있다.
ThreadLocal vs ScopedValue 비교
| 특성 | ThreadLocal | ScopedValue |
|---|---|---|
| 변경 가능성 | mutable (set/get) | immutable (바인딩 후 변경 불가) |
| 수명 관리 | 수동 remove() 필요 | 스코프 종료 시 자동 해제 |
| 상속 | InheritableThreadLocal (복사) | 자식 스레드와 참조 공유 (복사 없음) |
| 메모리 | 스레드당 해시맵 유지 | JVM 스택 기반, GC 부담 없음 |
| Virtual Thread 호환 | 메모리 누수 위험 | 설계 목적 자체가 Virtual Thread |
Virtual Threads, 프로덕션에 넣기 전에 거쳐야 할 관문
1. DB 커넥션 풀 — 세마포어로 보호하라
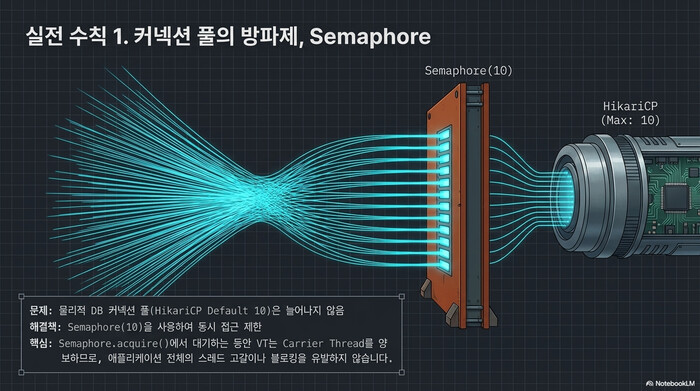
Virtual Thread가 수만 개 생성돼도 DB 커넥션 풀은 변하지 않는다. HikariCP 기본값은 10개이다. 동시 요청이 그 이상 들어오면 커넥션 대기열이 폭발한다. 처음 Java Virtual Threads를 적용하고 나서 가장 먼저 터지는 곳이 보통 여기이다.
import java.util.concurrent.Semaphore;
import org.springframework.stereotype.Service;
@Service
public class OrderService {
// DB 커넥션 풀 크기(10)에 맞춰 세마포어로 동시 접근 제한
private static final Semaphore DB_LIMITER = new Semaphore(10);
private final OrderRepository orderRepository;
OrderService(OrderRepository orderRepository) {
this.orderRepository = orderRepository;
}
public Order findOrder(Long id) throws InterruptedException {
DB_LIMITER.acquire(); // 커넥션 풀 크기 초과 방지
try {
return orderRepository.findById(id)
.orElseThrow();
} finally {
DB_LIMITER.release();
}
}
}Semaphore의 permit 수를 HikariCP의 maximumPoolSize와 맞추는 게 포인트이다. Virtual Thread가 아무리 많아도 동시에 DB를 때리는 건 10개로 제한된다. Semaphore.acquire()에서 대기할 때 carrier thread를 양보하므로, 대기 중인 Virtual Thread가 다른 작업을 막지 않는다.
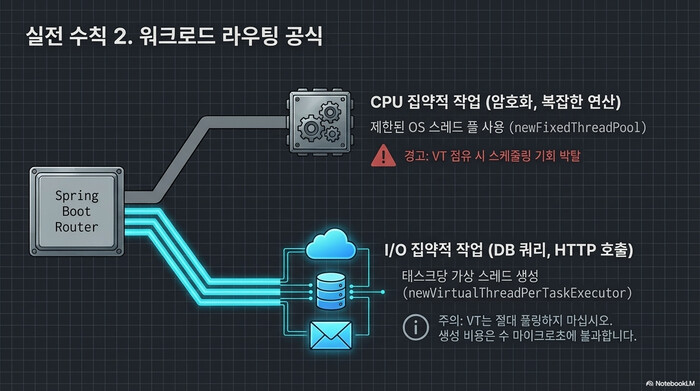
2. CPU 바운드 작업은 분리하라
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
@Configuration
public class ExecutorConfig {
// CPU 바운드 작업 전용 — platform thread 풀 사용
@Bean("cpuBoundExecutor")
public ExecutorService cpuBoundExecutor() {
return Executors.newFixedThreadPool(
Runtime.getRuntime().availableProcessors() // CPU 코어 수만큼
);
}
// I/O 바운드 작업 전용 — Virtual Thread 사용
@Bean("ioBoundExecutor")
public ExecutorService ioBoundExecutor() {
return Executors.newVirtualThreadPerTaskExecutor();
}
}CPU 바운드 작업(암호화, 이미지 처리, 복잡한 계산)은 newFixedThreadPool로, I/O 바운드 작업(DB 쿼리, HTTP 호출, 파일 읽기)은 newVirtualThreadPerTaskExecutor로 분리한다. Virtual Thread에서 CPU를 오래 쓰면 carrier thread를 장시간 점유해서 다른 Virtual Thread가 스케줄링 기회를 잃는다. I/O 대기가 거의 없는 작업은 Virtual Thread에 태울 이유가 없다.
3. Virtual Thread는 풀링하지 마라
// 잘못된 패턴 — Virtual Thread를 풀링하면 안 된다
ExecutorService wrong = Executors.newFixedThreadPool(100,
Thread.ofVirtual().factory()); // Virtual Thread인데 풀 크기 제한?
// 올바른 패턴 — 태스크마다 새로 생성
ExecutorService correct = Executors.newVirtualThreadPerTaskExecutor();Virtual Thread의 생성 비용은 일반 객체 할당 수준(수 마이크로초)이다. 풀링은 platform thread의 높은 생성 비용을 절감하기 위한 기법이었으므로, Virtual Thread에 풀을 적용하면 오히려 확장성을 제한하는 역효과가 난다.
4. JDBC 드라이버 호환성 확인
대부분의 JDBC 드라이버는 Java Virtual Threads와 잘 돌아간다. 다만 내부에 synchronized를 과하게 쓰거나 네이티브 코드를 호출하는 드라이버는 여전히 pinning을 유발할 수 있다.
# application.yml — HikariCP 설정 최적화
spring:
datasource:
hikari:
maximum-pool-size: 10 # Virtual Thread 환경에서도 변경 불필요
connection-timeout: 3000 # 커넥션 대기 타임아웃 (ms)
leak-detection-threshold: 5000 # 커넥션 누수 감지 임계값 (ms)HikariCP의 maximum-pool-size는 Virtual Thread를 사용해도 키울 필요가 없다. DB 자체의 최대 동시 연결 수가 병목이므로, 커넥션 풀 크기는 DB 용량에 맞춰 설정한다.
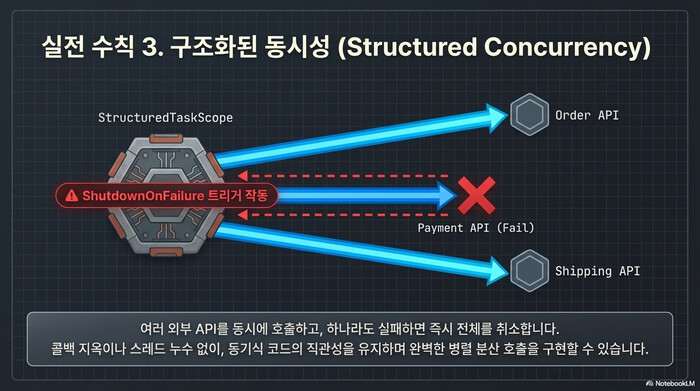
Structured Concurrency로 여러 호출을 묶어 관리하기
Structured Concurrency는 아직 프리뷰 단계(JDK 26 기준)이지만, Virtual Threads와 조합하면 실무에서 자주 만나는 “여러 API를 동시에 호출하고 하나라도 실패하면 전부 취소”하는 패턴을 깔끔하게 처리할 수 있다.
스레드 누수는 이제 그만! Structured Concurrency 소개 (ft. JDK 25) 참고
import java.util.concurrent.StructuredTaskScope;
// --enable-preview 필요 (JDK 26 기준 6th preview)
public class OrderAggregator {
record OrderDetails(Order order, Payment payment, Shipping shipping) {}
OrderDetails fetchOrderDetails(Long orderId) throws Exception {
// ShutdownOnFailure: 하나라도 실패하면 나머지 자동 취소
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
// 세 API를 동시에 호출 — 각각 별도 Virtual Thread에서 실행
var orderTask = scope.fork(() -> orderClient.getOrder(orderId));
var paymentTask = scope.fork(() -> paymentClient.getPayment(orderId));
var shippingTask = scope.fork(() -> shippingClient.getShipping(orderId));
scope.join(); // 모든 태스크 완료 대기
scope.throwIfFailed(); // 실패한 태스크가 있으면 예외 전파
return new OrderDetails(
orderTask.get(),
paymentTask.get(),
shippingTask.get()
);
}
}
}ShutdownOnFailure가 핵심이다. fork된 태스크 중 하나라도 예외를 던지면 나머지를 자동으로 취소한다. 세 개의 외부 API 호출이 각각 별도 Virtual Thread에서 실행되지만, try-with-resources 블록이 끝나면 전부 정리된다. 스레드 누수 걱정 없이 병렬 호출을 구현할 수 있다.
마치며 — 어디에 쓰고, 어디에 쓰지 말아야 하는가
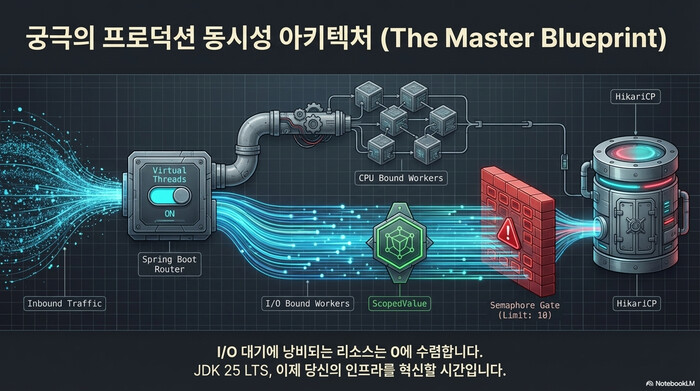
돌이켜보면 Java Virtual Threads가 해결하는 문제는 명확하다. “I/O 대기 시간에 OS 스레드를 낭비하지 않겠다”는 것이다. 그래서 효과를 보려면 워크로드가 I/O 바운드여야 한다. DB 쿼리, 외부 API 호출, 파일 읽기가 주된 작업인 Spring MVC 애플리케이션이라면 application.yml 한 줄로 처리량이 2~3배 늘어나는 경험을 할 수 있다.
반대로, CPU를 꽉 채워 쓰는 배치 연산이나 이미지 프로세싱 서비스에서는 Virtual Threads가 별 도움이 되지 않는다. 필자의 경우에도 실무에서 Virtual Threads를 적용했을 때 가장 큰 실수가 “모든 작업에 Virtual Thread를 쓰면 되겠지”라는 생각이었다. CPU 바운드 작업은 별도 ForkJoinPool로 분리하고, I/O 바운드 작업만 Virtual Thread에 태운 뒤에야 기대한 성능 개선을 확인할 수 있었다.
JDK 25 LTS를 프로덕션 기준선으로 잡으면, pinning 해결(JEP 491, JDK 24)과 ScopedValue 정식화(JEP 506, JDK 25)가 모두 들어있다. Structured Concurrency가 아직 프리뷰라 아쉽긴 하지만, Executors.newVirtualThreadPerTaskExecutor()와 Semaphore 조합만으로도 프로덕션에서 쓸 만한 동시성 모델은 충분히 만들 수 있다.