
운영 중인 Spring Boot 애플리케이션에서 배치 실행 주기를 30분마다에서 10분마다로 바꿔 달라는 요청을 받아본 적이 있다면 이 주제가 익숙할 것이다. @Scheduled(cron = "0 */30 * * * *") 같은 어노테이션은 값이 소스 코드에 박혀 있어 주기를 바꾸려면 재배포가 필요하다. 반면 Spring Boot 동적 Cron 스케줄링을 도입하면 DB 테이블 한 행만 수정해도 다음 실행부터 새 주기가 흐르기 시작한다. 이번 포스팅에서는 Spring Boot 동적 Cron 스케줄링을 구현하는 두 가지 실전 패턴, 2026년 기준 최신 Trigger API의 Lenient/Fixed 실행 모드, 운영 단계에서 반드시 점검해야 할 항목을 정리하고자 한다.
왜 @Scheduled는 운영 단계에서 발목을 잡는가
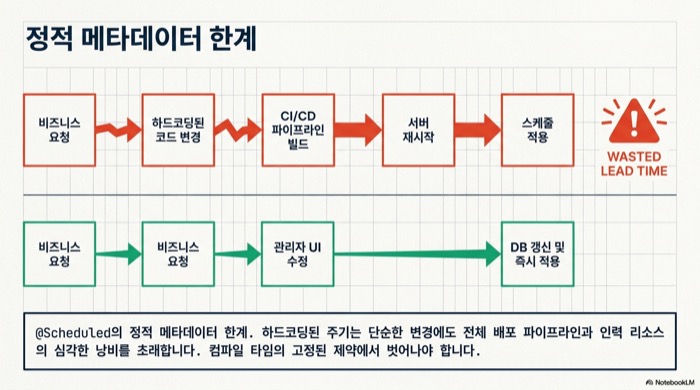
@Scheduled 어노테이션은 Spring이 애플리케이션 시작 시점에 메타데이터를 읽어 스케줄을 고정한다. 따라서 런타임에 표현식을 갈아끼울 수 없다. 세일 프로모션 직전에 동기화 주기를 좁혀야 하거나 장애 대응 중 배치 실행 시간을 늦춰야 할 때처럼, 배포 없이 주기를 조정해야 하는 상황에서는 이 정적 성격이 그대로 병목이 된다.
사용자 단위 알림 발송, 외부 결제 시스템 정산 같은 업무는 운영팀이 기준 시각을 자주 조정한다. 이때 개발자가 매번 @Scheduled 값을 바꾸고 CI/CD 파이프라인을 돌리는 구조는 인력과 리드타임 모두 낭비다. 실무에서는 관리자 화면에서 Cron 표현식을 편집하면 즉시 반영되는 흐름이 훨씬 자연스럽다. Spring Boot 동적 Cron 스케줄링이 필요한 이유가 여기에 있다.
@Scheduled 어노테이션이 가진 기본 한계
Spring은 @Scheduled의 cron, fixedRate, fixedDelay 속성을 ScheduledAnnotationBeanPostProcessor가 초기 스캔 시 한 번만 파싱한다. 이 속성에 넣은 문자열 리터럴은 빈이 생성된 이후에는 수정할 방법이 사실상 없다. 컴파일 타임에 고정된 스케줄만 허용한다는 뜻이다.
한 가지 우회로는 @Scheduled의 cron 속성에 SpEL 표현식을 넣어 외부 Bean 메서드를 호출하는 것이다. 이 방법도 완전 동적은 아니지만 프로퍼티 값 변경과 애플리케이션 컨텍스트 리프레시 조합으로 상당수 요구를 커버한다. 그보다 더 깊이 DB 값을 매 실행마다 반영하려면 SchedulingConfigurer를 직접 구현해야 한다. 두 접근 모두 기본 어노테이션 한계를 인식하는 데서 출발한다.
첫 번째 패턴 — Bean 메서드로 표현식을 공급하기

Spring Boot 동적 Cron 스케줄링을 가볍게 시작하려면 @Scheduled(cron = "#{@cronProvider.expression()}") 형태로 SpEL을 통해 Bean에서 값을 가져오는 방식이 쓸 만하다. 설정을 application.yml 바깥으로 분리할 때 유용하지만 런타임 갱신에는 컨텍스트 리프레시가 필요하다는 점을 분명히 알아야 한다. 진정한 런타임 반영을 기대하면 안 된다.
@Component("cronProvider")
public class CronExpressionProvider {
private final CronJobRepository repository;
public CronExpressionProvider(CronJobRepository repository) {
this.repository = repository;
}
// @Scheduled가 시작 시점에 한 번 호출한다
public String expression() {
return repository.findByName("daily-report")
.map(CronJob::getExpression)
.orElse("0 0 6 * * *"); // 기본값: 매일 오전 6시
}
}위 코드에서 expression() 메서드는 @Scheduled가 Bean 초기화 시점에 단 한 번 평가한다. DB 값을 읽어오지만 스케줄이 등록되고 나면 이후 값 변경은 반영되지 않는다. 이 패턴은 ‘배포 시점마다 달라질 수 있는 값’을 코드 바깥으로 뽑아내는 용도로만 적합하다.
@Component
public class ReportScheduler {
@Scheduled(cron = "#{@cronProvider.expression()}")
public void sendDailyReport() {
// 실제 리포트 발송 로직
}
}어노테이션 속성에 SpEL(#{...})을 넣으면 컨텍스트의 cronProvider Bean을 찾아 expression() 메서드를 호출한다. 문자열 리터럴과 동일한 타이밍으로 평가되지만 값의 출처가 코드가 아닌 Bean이라 설정 변경이나 다중 환경 대응이 쉬워진다. 약점은 런타임 반영이 불가능하다는 한 가지뿐이다.
두 번째 패턴 — SchedulingConfigurer로 실행마다 DB를 조회하기
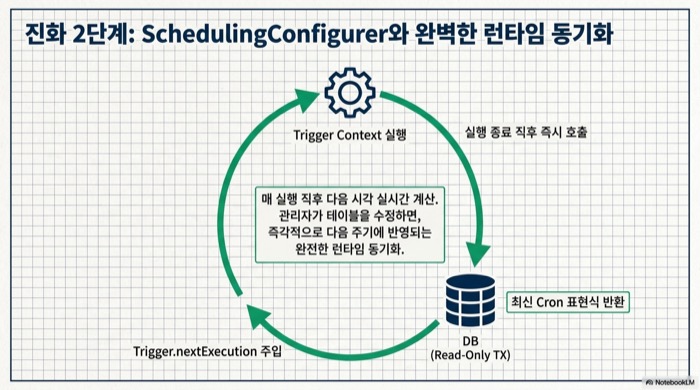
완전한 Spring Boot 동적 Cron 스케줄링은 SchedulingConfigurer를 구현하고 addTriggerTask로 Trigger 람다를 등록해 해결한다. Trigger.nextExecution이 매 실행 직후 호출되므로, 이 시점에 DB에서 최신 Cron 표현식을 읽어오면 재배포 없이 주기가 즉시 반영된다.
@Configuration
@EnableScheduling
public class DynamicCronConfig implements SchedulingConfigurer {
private final CronJobRepository repository;
public DynamicCronConfig(CronJobRepository repository) {
this.repository = repository;
}
@Bean
public TaskScheduler taskScheduler() {
ThreadPoolTaskScheduler scheduler = new ThreadPoolTaskScheduler();
scheduler.setPoolSize(5); // 동시 실행 가능한 스케줄 수
scheduler.setThreadNamePrefix("dyn-cron-");
scheduler.initialize();
return scheduler;
}
@Override
public void configureTasks(ScheduledTaskRegistrar registrar) {
registrar.setTaskScheduler(taskScheduler());
registrar.addTriggerTask(
this::sendDailyReport,
triggerContext -> {
String expression = repository.findByName("daily-report")
.map(CronJob::getExpression)
.orElse("0 0 6 * * *");
return new CronTrigger(expression).nextExecution(triggerContext);
}
);
}
private void sendDailyReport() {
// 실제 리포트 발송 로직
}
}이 설정의 핵심은 addTriggerTask에 전달하는 두 번째 람다다. TriggerContext가 넘어올 때마다 DB에서 최신 표현식을 조회해 CronTrigger를 새로 생성하고, 그 Trigger가 계산한 다음 실행 시각을 돌려준다. 관리자가 테이블 값을 바꾸면 현재 실행이 끝나자마자 새 주기가 적용된다는 뜻이다. 매 실행마다 DB를 한 번씩 조회한다는 점만 감안하면 가장 깔끔한 패턴이다.
Lenient와 Fixed — 2026년에 꼭 알아야 할 실행 모드
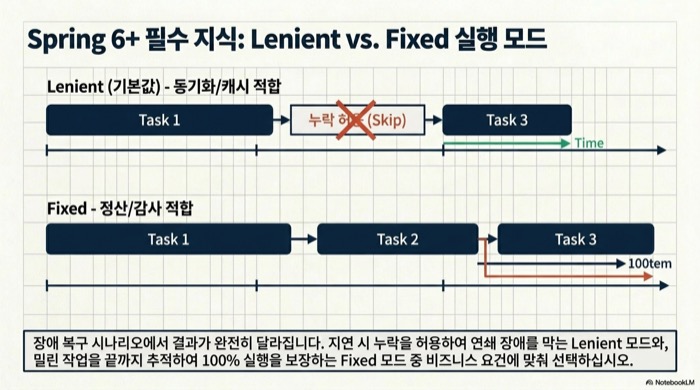
Spring Framework 6부터 CronTrigger는 기본적으로 lenient execution으로 동작한다. 이전 작업이 아직 끝나지 않았다면 놓친 fire(다음 실행)를 보상하지 않고 다음 예약만 잡는 방식이다. 반대로 fixed execution은 마지막 예정 시각을 기준으로 밀린 분량을 전부 따라 잡는다. 운영 성격에 따라 선택이 갈린다.
// lenient(기본) — 완료 시점 기준, 놓친 발화 보상 없음
Trigger lenient = CronTrigger.forLenientExecution("0 */5 * * * *");
// fixed — 예정 시각 기준, 놓친 분량 순차 실행
Trigger fixed = CronTrigger.forFixedExecution("0 */5 * * * *");두 팩토리 메서드는 겉보기에는 비슷하지만 장애 복구 상황에서 결과가 크게 갈린다. lenient는 실행이 오래 걸려 주기가 길어져도 중복을 유발하지 않고, fixed는 배치 누락을 허용하지 않아야 할 때 안전하다. 정산·감사 로그처럼 ‘한 번도 빠뜨리지 않아야 한다’는 요건에는 fixed가, 동기화·캐시 워밍처럼 ‘최신 상태만 맞으면 된다’는 요건에는 lenient가 어울린다.
Lenient execution과 fixed execution 동작 예시
이해를 돕기 위해 Lenient execution과 Fixed execution 동작을 예로 들면 다음과 같다.
Lenient (기본값)
마지막 완료 시점 기준으로 다음 실행을 계산한다.
Cron: 매 5분 (0 */5 * * * *)
00:00 작업 시작
00:08 작업 완료 (3분 초과로 00:05 fire를 놓침)
00:10 다음 실행 ← 완료 시점(00:08) 이후 가장 가까운 cron 매칭 시각
- 놓친 00:05 fire는 그냥 건너뛴다
- 작업이 오래 걸려도 중복 실행이 발생하지 않는다
- 캐시 워밍, 동기화처럼 “최신 상태만 맞으면 되는” 작업에 적합하다
Fixed
마지막 예정 시각 기준으로 다음 실행을 계산한다.
Cron: 매 5분 (0 */5 * * * *)
00:00 작업 시작
00:08 작업 완료 (00:05 fire를 놓침)
00:08 즉시 00:05분 밀린 작업 실행 ← 놓친 fire를 따라잡는다
00:10 정상 실행
- 놓친 fire를 순차적으로 전부 보상한다
- 한 건도 빠뜨리면 안 되는 정산, 감사 로그에 적합하다
- 위험: 작업이 계속 지연되면 밀린 분량이 쌓여 스레드풀이 막힐 수 있다
정산, 감사 로그, 시계열 데이터 수집처럼 시간 구간별로 빠짐없이 처리해야 하는 작업이 Fixed의 용도다. 반대로 “지금 시점의 최신 상태만 반영하면 되는” 캐시 갱신이나 헬스체크는 놓친 과거 시점을 따라잡을 이유가 없으니 Lenient를 사용한다.
더 자세한 의미 차이는 Spring Framework 공식 CronTrigger Javadoc에 정리되어 있다. Spring Boot 동적 Cron 스케줄링을 도입할 때 두 모드 중 하나를 의식적으로 선택해야 나중에 문제가 터지지 않는다.
Spring Boot 동적 Cron 실전 예제 — CronJob 엔티티와 JPA 조회
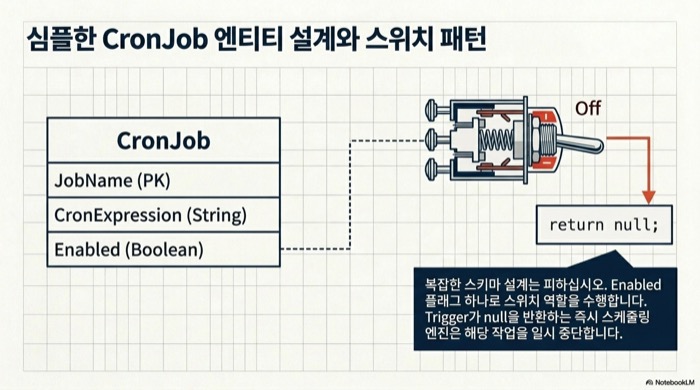
@Entity
@Table(name = "cron_jobs")
public class CronJob {
@Id
private String name;
@Column(nullable = false)
private String expression;
@Column(nullable = false)
private boolean enabled;
// getter/setter 생략
}엔티티는 단순하다. 이름으로 식별하고, 표현식과 활성화 플래그만 둔다. 운영에서 특정 작업을 일시 중지하려면 enabled 컬럼을 false로 바꿔 Trigger 람다가 다른 분기로 빠지도록 처리하면 된다. 스키마를 복잡하게 가져가면 관리자 화면 구현도 무거워지므로 이 수준이 적당하다.
public interface CronJobRepository extends JpaRepository<CronJob, String> {
Optional<CronJob> findByName(String name);
}Spring Data JPA의 네이밍 쿼리만 있으면 조회에 충분하다. Trigger 람다 안에서 리포지토리를 그대로 호출해도 되지만, 한 가지 주의할 점은 람다가 스케줄러 스레드에서 실행되므로 트랜잭션 전파 설정을 명시적으로 확인해야 한다는 것이다. 별도 @Transactional(readOnly = true) 메서드로 한 번 감싸 두면 커넥션이 누수되는 사고를 예방할 수 있다.
triggerContext -> {
Optional<CronJob> job = repository.findByName("daily-report");
if (job.isEmpty() || !job.get().isEnabled()) {
return null; // 작업 비활성화
}
return new CronTrigger(job.get().getExpression()).nextExecution(triggerContext);
}Trigger.nextExecution이 null을 반환하면 Spring은 해당 작업을 더 이상 스케줄링하지 않는다. 내부적으로 ReschedulingRunnable이 작업 완료 후 trigger.nextExecution()을 호출하는데, 여기서 null이 돌아오면 다음 실행을 예약하지 않고 스케줄링 루프 자체를 종료한다. 이후 DB에서 enabled를 다시 true로 바꿔도 Trigger를 호출해 줄 주체가 이미 사라진 상태이므로, 애플리케이션을 재시작하거나 태스크를 다시 등록하지 않는 한 작업이 재개되지 않는다.
운영팀이 관리자 화면에서 작업을 껐다 켤 수 있어야 한다면 null 대신 먼 미래 시각을 반환해 스케줄링 루프를 살려 두는 패턴이 안전하다.
triggerContext -> {
Optional<CronJob> job = repository.findByName("daily-report");
if (job.isEmpty() || !job.get().isEnabled()) {
// null 대신 1시간 뒤를 반환해 스케줄링 루프를 유지한다
return Instant.now().plusSeconds(3600);
}
return new CronTrigger(job.get().getExpression()).nextExecution(triggerContext);
}위 코드에서 enabled가 false인 동안에는 1시간마다 DB를 한 번씩 확인하며 루프가 살아 있다. 운영팀이 값을 true로 바꾸면 최대 1시간 이내에 정상 Cron 주기로 복귀한다. 폴링 간격(3600초)은 상황에 맞게 줄이거나 늘릴 수 있다.
폴링 간격(3600초)은 ‘복귀 속도 vs DB 부하’의 트레이드오프다. enabled를 true로 바꾸더라도 현재 대기 중인 폴링이 끝나야 Trigger 람다가 다시 호출되므로, 위 코드 기준으로 최대 1시간 후에 정상 주기가 반영된다. 간격을 줄이면 복귀는 빨라지지만 비활성 상태에서도 DB 조회가 잦아진다. 작업 수가 적다면 30초로 줄여도 부담이 없고, 수백 개 작업을 관리하는 환경이라면 5~10분이 현실적이다. 바로 반영되지 않아도 되는 상황이면 1시간(3600초) 정도 간격을 두는 것이 합리적인 것 같다.
Spring Boot 동적 Cron 운영 체크리스트 네 가지
Spring Boot 동적 Cron 스케줄링은 기능만 잘 만들어도 배포 빈도가 분명히 줄어든다. 다만 스레드풀, 캐시, 시간대, 관측성 중 어느 하나라도 놓치면 오히려 사고 빈도가 올라간다. 배포 전에는 아래 네 가지를 반드시 점검해야 한다.
첫째, ThreadPoolTaskScheduler의 pool size는 동시 실행될 작업 수보다 크게 잡아야 한다. 기본값이 1이라 작업 하나가 늘어지면 전체 스케줄이 막힌다. Spring Boot 3.2 이상(Spring Framework 6.1+)이라면 JDK 21의 가상 스레드를 쓰는 SimpleAsyncTaskScheduler를 고려할 수도 있다. 작업마다 가상 스레드를 새로 생성하는 thread-per-task 모델이라 풀 크기 설정 자체가 필요 없어진다.
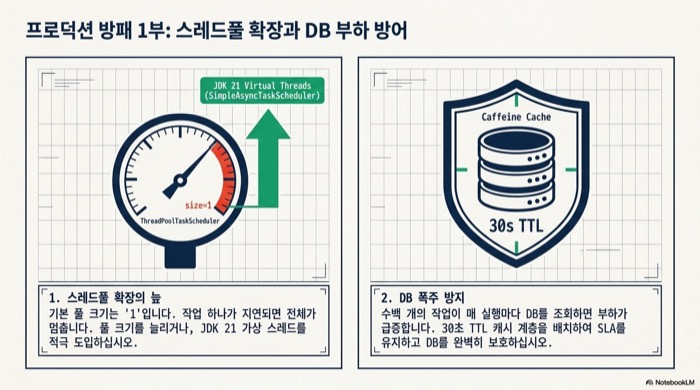
둘째, Trigger 람다에서 매번 DB를 조회하므로 Cron 표현식 개수가 많은 경우 캐시 계층을 두는 편이 좋다. Caffeine으로 30초 TTL을 두면 관리자가 화면에서 값을 바꾼 뒤 ’30초 이내 반영’이라는 SLA를 약속할 수 있다. 수백 개 작업 규모에서는 이 한 줄이 DB 부하 그래프를 완전히 바꿔 놓는다.
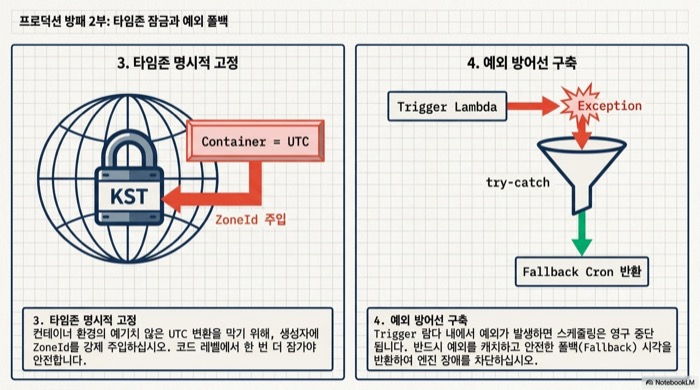
셋째, CronTrigger의 시간대다. 생성자에 ZoneId를 넘기지 않으면 JVM 기본 시간대를 따라간다. 컨테이너 기반 배포에서는 시간대가 UTC로 떨어져 있는 경우가 많아 KST 기준으로 표현식을 짰다가 오전 9시가 갑자기 오후 6시가 되어 버리는 실수를 흔히 본다.
new CronTrigger(expression, ZoneId.of("Asia/Seoul"));위와 같이 생성자에 명시적으로 ZoneId를 전달하면 JVM 기본 시간대와 무관하게 동작한다. 컨테이너 이미지 빌드 시 TZ 환경 변수를 설정하는 것만으로는 JVM이 이를 항상 반영한다는 보장이 없으므로, 코드 레벨에서 한 번 더 잠가 두는 편이 안전하다.
넷째, Trigger 람다에서 던지는 예외는 다음 실행을 멈추게 한다. 로깅과 함께 기본값으로 대체하거나, 폴백 Cron을 반환하는 구조를 만들어 두면 DB 장애 상황에서도 배치가 살아남는다. Spring Boot 동적 Cron 스케줄링의 장점은 말 그대로 ‘동적’인 데서 오지만, 동적이라는 단어가 곧 ‘예측 불가’라는 의미도 된다는 점을 잊으면 안 된다.
같은 목적, 다른 도구 — Quartz와의 분기점
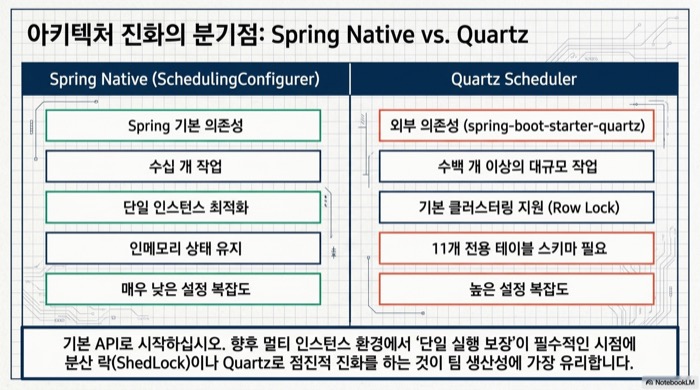
Spring Boot 동적 Cron 스케줄링을 구현하는 또 다른 선택지는 Quartz Scheduler를 붙이는 것이다. Quartz는 클러스터 환경에서 단일 실행을 보장하고, 트리거 상태 자체를 DB에 저장한다. 단점은 스키마 11개와 상대적으로 무거운 설정이다. 가벼운 배치에는 과하다는 뜻이다.
| 항목 | SchedulingConfigurer | Quartz |
|---|---|---|
| 의존성 | Spring 기본 | quartz, spring-boot-starter-quartz |
| 클러스터링 | 직접 구현 필요 | 기본 지원 (row lock 기반) |
| 트리거 상태 저장 | 애플리케이션 메모리 | 전용 테이블 11개 |
| 설정 복잡도 | 낮음 | 중간 |
| 적합한 규모 | 수십 개 작업 | 수백 개 이상, 멀티 인스턴스 |
단일 인스턴스에 수십 개 작업 환경이라면 SchedulingConfigurer 조합이 충분하다. 여러 서버가 동시에 돌면서 ‘딱 한 대만 실행해야 한다’는 요건이 생기면 Quartz 또는 ShedLock 같은 분산 락을 덧붙이는 쪽으로 진화시키면 된다. 처음부터 Quartz를 고르기보다 기본 API에서 시작해 필요해지는 시점에 갈아타는 방식이 팀 생산성에 더 유리하다고 생각한다.
ShedLock에 대해서는 Spring Boot 스케줄러 중복 실행 방지: ShedLock & Redis 적용 가이드 포스팅을 참고.
FAQ
Spring Boot 동적 Cron 스케줄링을 도입하면 서버 재시작 없이 주기가 바로 반영되는가?
SchedulingConfigurer + Trigger 람다 패턴은 매 실행이 끝난 직후 다음 실행 시각을 계산할 때 DB를 다시 조회하므로, 현재 실행 중인 작업이 끝나면 새 Cron 표현식이 즉시 반영된다. 반면 @Scheduled(cron = "#{...}") 방식은 Bean 초기화 시점에 한 번만 파싱되기 때문에 컨텍스트 리프레시 또는 재시작이 필요하다.
Trigger 람다가 예외를 던지면 어떻게 되는가?
Spring은 예외를 캐치해 로깅한 뒤 해당 태스크의 스케줄링을 중단한다. 즉 DB 장애로 한 번이라도 RuntimeException이 올라오면 배치가 사실상 멈춘다. 람다 내부에서 try-catch로 기본 Cron 표현식을 돌려주거나, null 대신 미래 시각을 반환해 다음 조회 기회를 남기는 방식으로 방어해야 한다.
@Scheduled와 SchedulingConfigurer를 같이 써도 되는가?
같이 쓸 수 있다. @EnableScheduling을 선언하면 @Scheduled 어노테이션 기반 작업과 SchedulingConfigurer에서 수동으로 등록한 작업이 동일한 TaskScheduler를 공유한다. 다만 두 경로에서 등록한 작업 수가 스레드풀 크기를 넘기지 않도록 poolSize를 조정해야 하며, 섞어 쓸 경우 ScheduledTaskHolder로 전체 목록을 한 번에 확인하는 습관이 필요하다.
Lenient와 Fixed 중 기본값으로 무엇을 선택해야 하는가?
대부분 업무는 Lenient가 안전하다. 작업이 오래 걸려 다음 fire를 놓치더라도 중복을 만들지 않는다. 정산·감사 로그처럼 ‘한 번도 빠뜨리지 않아야 하는’ 작업만 Fixed로 둔다. Fixed는 누적된 발화를 순차 실행하기 때문에 스레드풀이 막히는 연쇄 장애로 번질 수 있어 도입 전 부하 테스트가 필요하다.
Cron 표현식을 외부에서 수정했을 때 어떻게 모니터링해야 하는가?
관리자 화면에서 Cron 값을 변경할 때 감사 로그와 메트릭 태그를 남기고, ScheduledTaskHolder에 등록된 모든 작업의 nextExecution을 주기적으로 출력하는 건강성 엔드포인트를 만드는 것을 권장한다. Actuator에 커스텀 HealthIndicator로 구현해 두면 Prometheus·Grafana 대시보드에서 다음 실행 시각의 이상을 바로 감지할 수 있다.
마치며
운영 팀이 배치 주기를 자주 조정하는 프로젝트에서 @Scheduled 어노테이션만으로 버티다가 결국 한 달에 두세 번씩 배포 파이프라인을 도는 팀을 여러 번 봤다. 개인적으로는 초기 설계 단계부터 Spring Boot 동적 Cron 스케줄링을 넣어 두는 편이 인력과 배포 리스크 모두를 아낀다고 본다. 처음 이 패턴을 도입했을 때 Trigger 람다 안에서 트랜잭션 전파를 잘못 설정해 DB 커넥션을 다 잡아먹은 경험이 있는데, 그 이후로는 Trigger 내부 조회는 read-only 트랜잭션으로 고정하고 캐시를 기본으로 끼워 넣는 루틴을 만들었다.
여러 인스턴스에 걸쳐 단일 실행을 보장해야 한다면 Quartz나 ShedLock으로 분산 락을 덧붙이는 작업이 다음 과제가 된다. 기본 Spring 기능만으로 재배포 없는 스케줄 변경이 된다는 사실이 새삼 고맙게 느껴질 때가 있다. Trigger SPI가 깔끔하게 뽑혀 있어서 가능한 일이다.