
이번 포스팅에서는 claude-mem 플러그인에 대해서 정리하고자 한다. Claude Code를 실무에서 며칠만 써보면 금방 부딪히는 벽이 있는데, 어제 고생해서 찾아낸 모듈 구조나 네이밍 규칙을 오늘 새 세션에서 또 설명해야 한다는 점이다. claude-mem은 세션 중 발생한 모든 관찰을 자동으로 압축해 SQLite에 쌓아두고, 다음 세션이 열릴 때 관련 컨텍스트를 주입해서 이 문제를 해결한다. GitHub 스타 46,100개를 받은 이 플러그인을 두고 설치부터 MCP 검색 도구 활용, 그리고 반드시 알아야 할 포트 37777 보안 이슈까지 실전 관점에서 정리해 본다.
claude-mem 플러그인은 정확히 무엇을 기억해 주는가
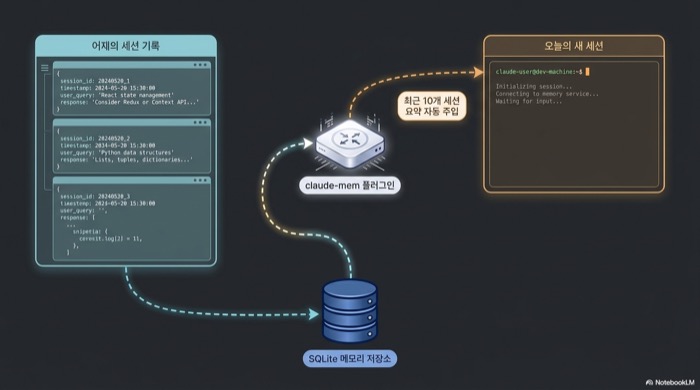
claude-mem 플러그인은 Claude Code의 다섯 개 라이프사이클 훅에 끼어들어 도구 호출 기록을 자동 수집하고, Claude Agent SDK로 의미론적 요약을 생성해 SQLite 데이터베이스에 저장하는 컨텍스트 압축 시스템이다. 수동으로 CLAUDE.md를 갱신할 필요 없이 새 세션이 열릴 때 최근 10개 세션의 요약이 자동 주입된다.
훅은 SessionStart, UserPromptSubmit, PostToolUse, Stop, SessionEnd 다섯 개다. 각 훅은 Read, Write, Bash 같은 도구가 무엇을 건드렸는지를 관찰(observation)로 기록한다. 이렇게 쌓인 관찰은 FTS5 기반 SQLite 풀텍스트 검색 인덱스와 Chroma 벡터 DB에 동시에 색인되어, 키워드와 시맨틱 검색을 섞은 하이브리드 쿼리가 가능해진다. 단순한 로그 파일이 아니라 질의 가능한 프로젝트 히스토리가 되는 셈이다. 버전 6.5.0 기준으로 Linux, macOS, Windows를 모두 지원하고, Claude Code 외에 Cursor, Gemini CLI, Windsurf, OpenClaw 게이트웨이와도 호환된다.
5분 설치 흐름: npx와 플러그인 마켓플레이스 중 무엇을 쓸까
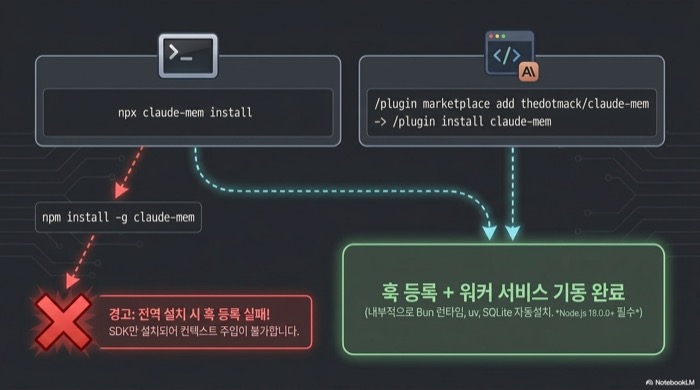
claude-mem 플러그인 설치는 두 가지 경로가 공식이다. 터미널에서 npx claude-mem install을 실행하거나, Claude Code 세션 안에서 /plugin marketplace add thedotmack/claude-mem에 이어 /plugin install claude-mem을 순서대로 호출하면 된다. 어느 쪽을 택해도 훅과 워커 서비스가 함께 등록된다.
# 방법 1: npx 설치 (터미널에서)
npx claude-mem install
# 방법 2: Claude Code 세션 안에서
/plugin marketplace add thedotmack/claude-mem
/plugin install claude-mem
# Gemini CLI에 함께 설치하려는 경우
npx claude-mem install --ide gemini-cli
# OpenCode에 설치하려는 경우
npx claude-mem install --ide opencode위 명령은 내부적으로 Bun 런타임, uv 파이썬 패키지 매니저, 그리고 번들된 SQLite를 차례로 확인하고 없으면 자동 설치한다. 시스템 요구사항은 Node.js 18.0.0 이상이며, 이 버전보다 낮으면 훅 등록 단계에서 실패한다. npx claude-mem install이 1회만 성공해도 이후 세션은 별도 조치 없이 바로 기억을 이어간다.
흔히 하는 실수가 하나 있다. npm install -g claude-mem로 전역 설치하는 방식인데, 이 경로는 SDK 라이브러리만 설치하고 훅 등록과 워커 서비스 기동을 건너뛴다. 분명 설치는 됐는데 새 세션에 컨텍스트가 전혀 안 나타난다면 전역 설치로 잘못 진행한 경우일 가능성이 가장 높다. 공식 문서도 이 점을 굵게 경고하고 있으므로 반드시 npx 또는 /plugin 경로를 써야 한다.
SessionStart부터 Stop까지, 5개 훅이 기억을 조립하는 순간
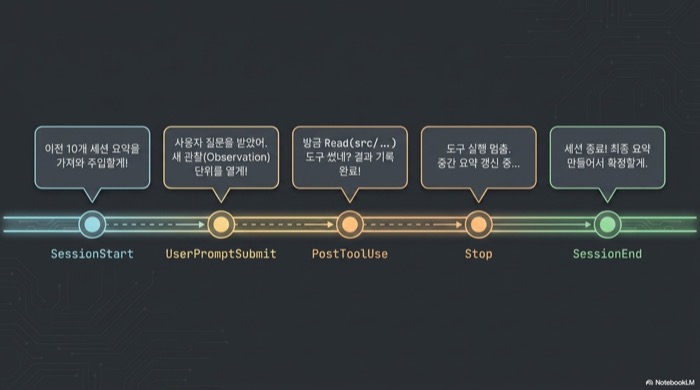
claude-mem 플러그인의 동작 원리는 다섯 개 훅이 각자 다른 시점에 관찰을 생성하고, 백그라운드 워커가 이를 요약해 데이터베이스에 적재하는 파이프라인이다. SessionStart에서 최근 10개 세션의 요약을 주입하고, Stop·SessionEnd에서 이번 세션의 관찰을 압축해 다음 세션을 위한 기록으로 남긴다.
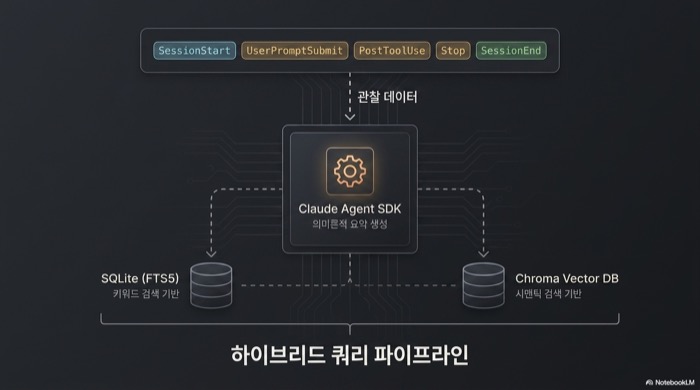
각 훅의 역할을 하나씩 보면 이렇다. SessionStart는 워커에 쿼리를 보내 관련 요약을 받아오고, UserPromptSubmit은 사용자 질문과 현재 시점을 엮어 새로운 관찰 단위를 연다. PostToolUse는 도구 호출 결과, 가령 Read(src/auth/login.ts) 같은 이벤트를 잡아 관찰로 적재한다. Stop은 도구 실행이 멈출 때 중간 요약을 갱신하고, SessionEnd는 세션 종료 시점에 최종 요약을 생성해 SQLite에 확정 저장한다.
워커 서비스는 Bun으로 동작하며 http://localhost:37777에서 HTTP API와 실시간 웹 UI를 제공한다. 이 웹 UI로 접속하면 각 관찰이 어떤 ID로 저장됐는지, 어느 세션 소속인지, 요약본이 어떻게 생성됐는지가 한눈에 보인다. 관찰마다 부여되는 ID는 MCP 검색 단계에서 그대로 참조되므로, 이상한 요약이 주입되기 시작했을 때 가장 먼저 들여다볼 창구이기도 하다.
settings.json으로 컨텍스트 주입을 길들이는 법

claude-mem 플러그인의 설정 파일은 ~/.claude-mem/settings.json에 자동 생성되며, 주입될 컨텍스트를 세밀하게 제어하는 11개 옵션을 제공한다. 첫 실행 직후에는 기본값만 들어 있으므로 프로젝트 언어나 민감 데이터 정책에 맞춰 손봐주는 것이 좋다. 공식 문서에서 가장 먼저 소개되는 옵션은 요약 언어를 바꾸는 CLAUDE_MEM_MODE다.
{
"CLAUDE_MEM_MODE": "code"
}CLAUDE_MEM_MODE는 요약 문체와 언어를 결정한다. 기본값 code는 영어 요약을 생성하고, code--zh(간체 중국어), code--ja(일본어) 같은 변형이 준비돼 있다. 한국어 전용 모드는 아직 공식 제공되지 않지만 code 모드로도 한국어 주석과 식별자는 그대로 보존된다. 모드를 변경한 뒤에는 Claude Code를 재시작해야 반영된다. 나머지 10개 옵션은 관찰 수 제한이나 자동 주입 세션 개수 같은 세부 제어용이며, 공식 문서에서 최신 키 목록을 확인하는 편이 안전하다.
민감 정보가 저장소에 들어가지 않게 하려면 프롬프트나 코드 블록 안에서 <private>와 </private> 사이에 내용을 감싸면 된다. claude-mem 플러그인은 이 태그 안쪽을 관찰 대상에서 제외하므로, 임시 API 키나 고객 데이터를 다룰 때 안전판 역할을 한다.
search · timeline · get_observations: 토큰 10배를 아끼는 3단 워크플로우

먼저 오해를 풀고 가자. search, timeline, get_observations는 사용자가 터미널이나 스크립트에서 직접 호출하는 함수가 아니다. claude-mem 플러그인이 MCP 프로토콜을 통해 Claude에게 노출하는 세 개의 검색 도구이고, 실제 호출은 Claude(LLM)가 프롬프트 맥락을 보고 알아서 수행한다. 사용자는 평소처럼 "지난주에 고친 인증 버그 뭐였더라?"라고 말하면 그만이다.
그런데 왜 굳이 세 개로 쪼갰을까. 한 번에 전체 본문을 긁어오는 단일 도구를 주지 않고 색인·시간축·본문을 분리해 둔 건, 반환 토큰 크기를 의도적으로 차등화해서 Claude가 자연스럽게 "색인 먼저, 본문은 나중에" 하는 깔때기 순서로 호출하도록 유도하기 위해서다. 아래는 Claude가 내부적으로 호출하는 MCP 툴 시그니처의 개념 예시다.
// 1단계: 압축된 색인만 받아온다 (결과당 약 50~100 토큰)
search({
query: "authentication bug",
type: "bugfix",
limit: 10
})
// 2단계: 특정 관찰 주변의 시간 흐름을 확인한다
timeline({
around_id: 123,
window: 5
})
// 3단계: 관련 ID만 골라서 전체 내용을 가져온다
get_observations({
ids: [123, 456]
})search는 FTS5 키워드 매칭과 Chroma 벡터 유사도를 함께 돌려 하이브리드 결과를 반환한다. 반환 결과에는 관찰 ID, 짧은 스니펫, 세션 소속, 타입 태그만 담겨서 10개를 받아도 1000 토큰 아래에서 끝난다. timeline은 특정 ID 주변의 관찰들을 시간순으로 펼쳐 보여주므로, 버그가 어떤 맥락에서 발견됐는지를 복원할 때 유용하다. 필요한 ID를 추렸다면 마지막으로 get_observations로 실제 본문을 불러온다.
정리하면 사용자가 설정할 것도, 스크립트로 따로 호출할 것도 없다. npx claude-mem install로 플러그인만 깔아두면 claude-mem이 이 세 툴을 Claude 앞에 내놓고, Claude는 툴 설명(tool description)에 담긴 권장 순서대로 움직인다. 반대로 이 3단 구조를 우회하고 처음부터 전체 본문을 긁어오도록 Claude를 유도하면 컨텍스트 윈도우가 금방 고갈되니, "전부 다 긁어와서 보여달라"는 식의 프롬프트만 피하면 된다.
포트 37777의 민낯: 설치 전 반드시 알아야 할 보안 이슈

claude-mem 플러그인을 클라우드 VM이나 공유 서버에서는 절대로 쓰면 안 된다. 2026년 2월 커뮤니티 보안 감사는 워커 서비스의 HTTP API(포트 37777)에 인증 수단이 전무하다는 이유로 claude-mem 플러그인을 HIGH 리스크로 분류했다. 같은 머신에 떠 있는 어떤 프로세스든 관찰 전체를 읽거나 임의의 메모리를 주입할 수 있다.
포트 37777은 기본값으로 localhost에만 바인딩되지만, 같은 OS 유저가 실행하는 프로세스라면 누구든 접근할 수 있다는 게 문제다. 악성 npm 패키지가 빌드 과정에서 이 포트로 쿼리를 던지면 과거 관찰이 통째로 유출될 수 있고, 반대로 허위 관찰을 주입해 다음 세션의 Claude Code를 유도할 수도 있다. 공식 권고도 명확하다. 개인 개발 머신에서만 쓰고, 공용 CI 러너나 쉐어드 서버에는 절대 설치하지 말라는 것이다.
실무에서는 팀 공용 빌드 서버나 GitHub Actions 러너에 claude-mem이 실수로 딸려 들어가지 않도록 설치 스크립트를 한번씩 점검해야 한다. 사내 보안 정책상 로컬 포트 오픈 자체가 금지된 환경이라면, 컨테이너 네트워크 네임스페이스로 격리하거나 방화벽으로 37777을 막은 뒤 쓸 수 있다. 민감 데이터 프로젝트라면 <private> 태그로 어떤 블록을 저장에서 제외할지 팀 차원에서 미리 합의해두고 첫 설치 명령을 실행하는 순서를 권한다.
어제 고친 버그를 오늘 또 만났을 때, 실전 워크플로우

claude-mem 플러그인이 실제로 빛을 보는 순간은 어제 해결한 문제를 오늘 다시 만났을 때다. 새 세션을 열자마자 “어제 로그인 토큰 만료 관련해서 뭐 했었지?”라고 물으면, 이전 세션에서 수정한 파일과 근거 코드가 자동으로 소환된다. 수동으로 git log를 뒤질 필요가 없다.
> 어제 로그인 토큰 만료 버그 고친 내용 다시 보여줘
[claude-mem injected]
최근 관찰 요약 (session_id: 2026-04-14-17:23):
- src/auth/token.ts:47에서 리프레시 토큰 TTL을 900s에서 3600s로 변경
- 원인: 클럭 스큐로 인해 유효 토큰이 만료 처리되는 케이스
- 관련 관찰 ID: 482, 483, 491
- 연관 테스트: src/auth/__tests__/token.test.ts 케이스 12번주입된 요약에는 수정한 파일 경로, 변경 수치, 근거, 연관 테스트까지 함께 담긴다. 여기서 추가 맥락이 필요하면 get_observations({ ids: [482, 483, 491] })로 전체 내용을 끌어오면 되고, 주변 흐름이 궁금하면 timeline으로 몇 개 관찰 앞뒤를 펼쳐 보면 된다. 팀원에게 인수인계 받는 것과 비슷한데, 인수인계를 해 주는 쪽이 어제의 나라는 점만 다르다.
요약이 모든 관찰을 무손실로 담지는 않는다는 점은 주의해야 한다. SessionEnd 시점에 Claude Agent SDK가 요약을 생성하는데, 이 과정에서 세부 수치가 누락되는 일이 종종 있다. 중요한 결정은 주입된 요약만 믿지 말고 get_observations로 원본 관찰을 한 번 더 확인하는 습관이 필요하다. 실제 코드는 git에 있고, claude-mem은 어디를 왜 고쳤는지를 되짚어주는 보조 도구 정도로 쓰는 게 현실적이다.
마치며

claude-mem을 몇 주 써본 소감을 한 줄로 줄이면 “편하지만 맹신하지 말 것” 정도가 된다. Claude Code 새 세션을 열 때마다 CLAUDE.md를 손보고 지난 결정들을 일일이 복사해서 붙여넣던 루틴이 사라진 건 분명한 이득이었다. 여러 프로젝트를 번갈아 만질 때 특히 그렇다. 각 저장소 폴더에 자동 생성되는 CLAUDE.md가 “이 프로젝트 최근에 뭐 건드렸지?”라는 질문을 혼자 답해주는 느낌이라 맥락 복원에 쓰던 시간이 꽤 줄었다.
다만 포트 37777 이야기는 가볍게 넘길 문제가 아니다. 개인 노트북에서만 쓰도록 선을 긋고, 사내 공용 서버에는 설치하지 않는다는 원칙을 팀 규약으로 적어두는 편이 안전하다. 개인적으로는 요약이 만능은 아니라는 점도 몇 번 체감했다. 요약본이 보여주는 그림과 실제 git 히스토리가 어긋난 적이 두 번 있었는데, 둘 다 짧은 커밋이 여러 개 섞인 리팩터링 세션이었다. 그 뒤로는 중요한 의사결정을 확인할 때 관찰 원본이나 git log로 한 번 더 돌려보는 습관이 생겼다.
FAQ
claude-mem 플러그인은 유료인가?
아니다. AGPL-3.0 라이선스로 공개된 오픈소스이며 npx claude-mem install만으로 무료 사용이 가능하다. 다만 저장소 내부의 ragtime 디렉터리는 별도의 Polyform 라이선스를 따른다는 점을 기억해야 한다. 상용 파생 제품을 만들 계획이라면 두 라이선스 조건을 모두 검토해야 한다.
npm install -g claude-mem로 설치해도 동일하게 동작하는가?
동작하지 않는다. 전역 설치는 SDK 라이브러리만 깔고 Claude Code의 훅 등록과 포트 37777 워커 서비스 기동을 건너뛴다. 설치는 성공한 것처럼 보이지만 새 세션에 컨텍스트가 전혀 주입되지 않는다. 반드시 npx claude-mem install 또는 /plugin install claude-mem 경로를 써야 한다.
민감한 고객 코드를 다루는데 claude-mem 플러그인이 기록할까봐 걱정된다
프롬프트나 코드 블록 안에서 <private>와 </private> 태그 사이에 감싼 내용은 관찰 수집 대상에서 제외된다. 공식 문서는 이 태그를 민감 데이터 분리용 1차 방어선으로 안내한다. 추가로 ~/.claude-mem/settings.json의 세부 옵션으로 관찰 저장 범위를 더 좁힐 수 있으므로, 설치 전 공식 문서에서 최신 옵션 목록을 한 번 훑어보는 편이 좋다.
이미 수백 개의 세션이 쌓였는데 검색이 느려지지 않나?
FTS5 풀텍스트 인덱스와 Chroma 벡터 DB를 함께 쓰기 때문에 수천 개 규모까지는 밀리초 단위로 응답한다. 다만 search로 바로 전체 본문을 불러오지 말고, ID만 먼저 받은 뒤 get_observations로 필요한 것만 조회하는 3단 워크플로우를 지켜야 토큰과 지연시간이 모두 절약된다.
Claude Code 외에 Cursor나 Gemini CLI에서도 쓸 수 있나?
쓸 수 있다. npx claude-mem install --ide gemini-cli, --ide opencode 같은 플래그로 대상을 지정하면 각 IDE 전용 훅이 등록된다. Cursor와 Windsurf, OpenClaw 게이트웨이까지 공식 지원 목록에 포함돼 있어서, 여러 AI 코딩 도구를 번갈아 쓰는 워크플로우에서도 하나의 SQLite에 관찰이 누적된다.
참고 자료
- claude-mem GitHub 저장소 (thedotmack/claude-mem)
- Claude-Mem 공식 문서
- DataCamp: Claude-Mem Guide
- Augment Code: claude-mem 46.1K 스타 분석