
OpenAI Java SDK를 직접 호출해 본 사람이라면 인증 헤더, 재시도 로직, 응답 파싱을 매 프로젝트마다 다시 짜는 일이 얼마나 지루한지 안다. Spring AI 2.0은 이 보일러플레이트를 ChatClient 한 줄로 줄이고, MCP(Model Context Protocol)를 코어에 내장해 외부 도구를 자연어 한 마디로 연결할 수 있게 했다. 이 글에서는 2026년 5월 기준 마일스톤 단계인 Spring AI 2.0의 네 축, 즉 ChatClient, MCP 통합, @Tool 기반 Function Calling, Java Record로 받는 Structured Output을 차례로 살펴본다. Spring Boot 4.1 위에서 LLM 애플리케이션을 Spring 답게 구성하는 출발점으로 활용하면 된다.
Spring AI 2.0이 1.x와 결정적으로 달라진 지점은 어디인가

Spring AI 2.0의 가장 큰 변화는 Spring Boot 4.1, Jackson 3, 공식 OpenAI Java SDK 기반으로 인프라를 갈아엎고 MCP Java SDK 2.0을 코어에 통합한 점이다. 1.x는 자체 RestClient로 LLM API를 호출했지만, 2.0은 OpenAI와 Anthropic이 공식 배포하는 Java SDK를 그대로 쓴다. 그래서 토큰 사용량 메트릭, 스트리밍 청크 처리, 미디어 타입 같은 디테일이 모델 제공자 표준과 어긋나지 않는다.
| 항목 | Spring AI 1.x | Spring AI 2.0 |
|---|---|---|
| 기반 Spring Boot | 3.5.x | 4.1.x |
| Jackson | 2 (com.fasterxml.jackson) | 3 (tools.jackson) |
| OpenAI 클라이언트 | 자체 RestClient | 공식 openai-java SDK |
| Anthropic 클라이언트 | 자체 RestClient | 공식 Anthropic Java SDK |
| MCP Java SDK | 0.x (커뮤니티) | 2.0.0-M2 (코어 통합) |
| Azure OpenAI | 별도 모듈 | spring-ai-openai에 통합 |
표에서 짚어둘 포인트는 두 가지다. Jackson 3 전환은 의존성을 타고 광범위하게 퍼지기 때문에, 1.x에서 2.0으로 갈아탈 때 직렬화/역직렬화 코드 곳곳에서 import가 깨진다. 다만 jackson-annotations만은 호환을 위해 com.fasterxml.jackson 네임스페이스를 유지한다는 예외가 있다. 그리고 MCP가 커뮤니티 모듈에서 코어로 옮겨온 것은 Spring 진영이 LLM 도구 생태계의 표준을 MCP로 가져가겠다는 신호다. 자세한 변경 내역은 Spring AI 2.0.0-M5 릴리즈 노트에 있다. 2026년 5월 1일 현재 최신 마일스톤은 M5(4월 27일 릴리즈)이며 GA는 아직 발표 전이다.
ChatClient를 어떻게 5분 만에 띄울 수 있을까
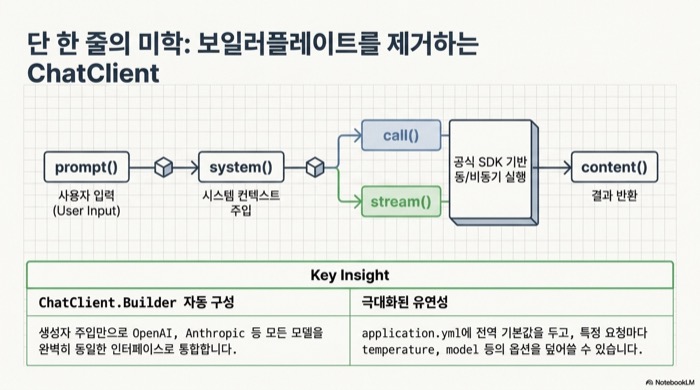
Spring AI 2.0의 ChatClient는 prompt() → user()/system() → call() → content()로 이어지는 fluent API다. Spring Boot 자동구성이 ChatClient.Builder를 빈으로 등록하므로, 생성자 주입만 받으면 OpenAI든 Anthropic이든 같은 인터페이스로 호출할 수 있다. 컨트롤러 한 개로 GPT 응답을 그대로 돌려주는 게 가장 짧은 예제다.
먼저 의존성을 정의한다. 2.0은 아직 마일스톤 단계이므로 Spring 마일스톤 저장소를 추가해야 한다.
plugins {
id 'org.springframework.boot' version '4.1.0-RC1'
id 'io.spring.dependency-management' version '1.1.7'
}
dependencies {
implementation platform('org.springframework.ai:spring-ai-bom:2.0.0-M5')
implementation 'org.springframework.ai:spring-ai-starter-model-openai'
}
repositories {
mavenCentral()
maven { url 'https://repo.spring.io/milestone' }
}위 build.gradle은 Spring AI BOM으로 모든 Spring AI 모듈의 버전을 일괄 정렬한다. spring-ai-starter-model-openai 스타터는 OpenAI ChatModel과 EmbeddingModel을 자동구성하며 BOM에 묶여 있어 별도 버전 지정 없이 그대로 가져온다. Spring Boot 4.1과 Spring AI 2.0 모두 GA 전 단계이므로 RC/마일스톤 버전을 사용해야 하고, GA 이후에는 마일스톤 저장소 라인을 제거해도 된다.
application.yml에 모델 설정을 추가한다.
spring:
ai:
openai:
api-key: ${OPENAI_API_KEY}
chat:
options:
model: gpt-4o-mini
temperature: 0.7API 키는 환경 변수로 주입하는 것이 안전하다. chat.options에 둔 model과 temperature는 ChatClient 호출 시 매번 덮어쓸 수 있다. 즉 전역 기본값을 yml에 두고, 특정 요청마다 옵션을 변경하는 패턴이 가능하다.
이제 컨트롤러를 작성한다.
@RestController
class ChatController {
private final ChatClient chatClient;
ChatController(ChatClient.Builder builder) {
this.chatClient = builder
.defaultSystem("너는 한국어로 답변하는 친절한 어시스턴트다.")
.build();
}
@GetMapping("/ai")
String chat(@RequestParam String message) {
return chatClient.prompt()
.user(message)
.call()
.content();
}
}ChatClient.Builder는 Spring Boot가 자동으로 주입해 주는 빈이다. defaultSystem에 시스템 프롬프트를 박아두면 이 ChatClient 인스턴스의 모든 호출에 같은 프롬프트가 붙는다. call().content()은 동기 호출이고, 토큰 사용량까지 받고 싶을 때는 chatResponse()를 쓴다. 스트리밍은 stream().content()로 Flux<String>을 받아 SSE로 흘려보내면 된다. ChatClient API 자체는 공식 ChatClient 문서에 자세하다.
MCP 서버를 @McpTool 어노테이션 하나로 만들 수 있을까
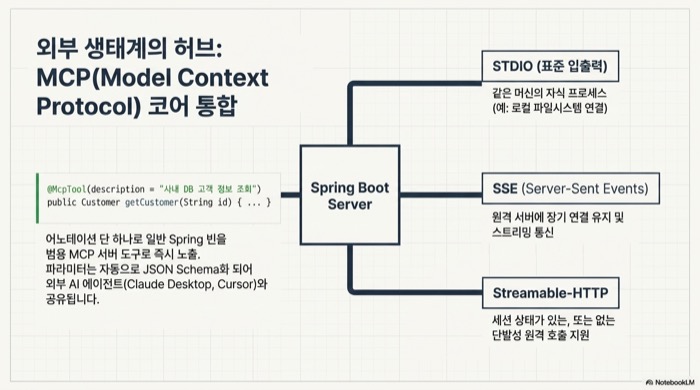
Spring AI 2.0에서는 @McpTool이 붙은 빈 메서드가 자동으로 MCP 서버 도구로 노출된다. 프로토콜 메시지를 직접 다룰 필요 없이 일반 Spring 컴포넌트처럼 도구를 작성하면 된다. transport는 4종을 지원하고 SYNC/ASYNC 모드도 yml 한 줄로 바뀐다.
transport (spring.ai.mcp.server.protocol) | 통신 방식 | 주 용도 |
|---|---|---|
STDIO (stdio: true 별도 옵션) | 표준 입출력 | 같은 머신에서 자식 프로세스로 띄울 때 |
| SSE | HTTP + Server-Sent Events | 원격 서버에 장기 연결을 유지할 때 |
| STREAMABLE (stateful 모드) | HTTP 스트리밍 | 세션 상태가 있는 원격 호출 |
| STREAMABLE (stateless 모드) | HTTP 스트리밍 | 세션 없이 단발성 호출 |
MCP 서버를 외부 LLM 도구 게이트웨이로 띄워두면 MCP 표준을 따르는 Claude Desktop이나 Cursor 같은 다른 클라이언트도 그대로 연결된다. 사내 데이터 조회 도구를 한 번 노출해 두면 IDE/데스크톱 어디서든 재사용할 수 있다는 의미다.
서버 측 의존성과 yml은 다음과 같다.
dependencies {
implementation platform('org.springframework.ai:spring-ai-bom:2.0.0-M5')
implementation 'org.springframework.ai:spring-ai-starter-mcp-server-webflux'
}spring:
ai:
mcp:
server:
type: SYNC
annotation-scanner:
enabled: truespring-ai-starter-mcp-server-webflux 스타터는 SSE transport 기반 MCP 서버를 자동구성한다. 실제 transport는 서버 스타터(-webflux, -webmvc) 선택과 spring.ai.mcp.server.protocol 속성 조합으로 결정된다. annotation-scanner.enabled: true는 클래스패스에서 @McpTool 어노테이션을 스캔해 도구로 등록하라는 지시이고, type은 SYNC(동기) 또는 ASYNC(Reactor 기반)를 고른다.
도구는 그냥 Spring 빈에 메서드를 정의하면 된다.
import org.springframework.ai.mcp.annotation.McpTool;
import org.springframework.ai.mcp.annotation.McpToolParam;
import org.springframework.stereotype.Component;
@Component
public class CalculatorTools {
@McpTool(name = "add", description = "두 정수를 더한다")
public int add(
@McpToolParam(description = "첫 번째 숫자", required = true) int a,
@McpToolParam(description = "두 번째 숫자", required = true) int b) {
return a + b;
}
@McpTool(name = "multiply", description = "두 정수를 곱한다")
public int multiply(int a, int b) {
return a * b;
}
}@McpTool description은 LLM이 어느 도구를 부를지 결정하는 핵심 단서다. “두 정수를 더한다”처럼 도구의 책임을 한 문장으로 적어야 모델이 정확히 매칭한다. 두 번째 메서드처럼 @McpToolParam이 없는 파라미터도 Spring이 메서드 시그니처에서 자동으로 JSON Schema를 만들어 클라이언트에 노출한다. 자세한 옵션은 MCP Server Boot Starter 문서에 있다.
MCP 클라이언트는 ChatClient에 어떻게 묶이는가
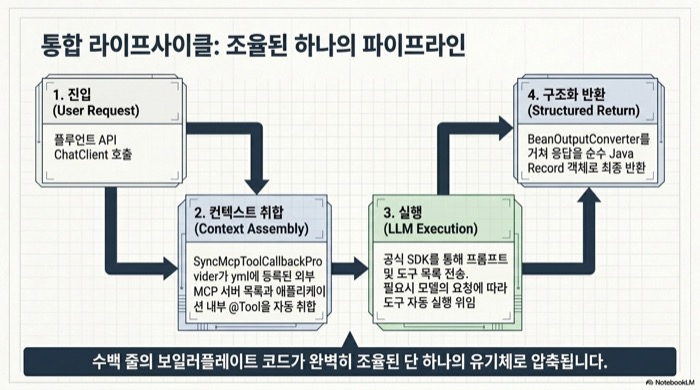
MCP 클라이언트 쪽은 SyncMcpToolCallbackProvider가 자동구성된다. 이 빈은 ChatClient의 .tools()에 바로 넣을 수 있는 ToolCallback[]을 돌려준다. LLM이 자연어 요청을 받으면 Spring AI가 등록된 모든 MCP 서버의 도구 목록을 모델에 함께 전달하고, 모델이 내려준 함수 호출 응답을 받아 해당 MCP 서버로 위임한다. 개발자가 직접 짜는 코드는 ChatClient 호출 한 줄이다.
dependencies {
implementation platform('org.springframework.ai:spring-ai-bom:2.0.0-M5')
implementation 'org.springframework.ai:spring-ai-starter-mcp-client'
implementation 'org.springframework.ai:spring-ai-starter-model-openai'
}spring:
ai:
mcp:
client:
enabled: true
name: my-mcp-client
version: 1.0.0
request-timeout: 30s
type: SYNC
toolcallback:
enabled: true
stdio:
connections:
filesystem:
command: npx
args:
- -y
- "@modelcontextprotocol/server-filesystem"
- /tmp
sse:
connections:
calculator:
url: http://localhost:8080위 yml은 두 종류의 MCP 서버를 동시에 연결한다. stdio.connections.filesystem은 자식 프로세스로 npx를 띄워 표준 입출력으로 통신하고, sse.connections.calculator는 앞서 만든 SSE 서버를 HTTP로 호출한다. toolcallback.enabled: true는 MCP 도구를 Spring AI의 ToolCallback으로 자동 변환하는 옵션이다.
서비스 코드는 ToolCallbackProvider를 주입해 ChatClient에 연결한다.
@Service
public class AiService {
private final ChatClient chatClient;
private final SyncMcpToolCallbackProvider toolCallbackProvider;
public AiService(ChatClient.Builder builder,
SyncMcpToolCallbackProvider toolCallbackProvider) {
this.toolCallbackProvider = toolCallbackProvider;
this.chatClient = builder.build();
}
public String ask(String question) {
return chatClient.prompt(question)
.tools(toolCallbackProvider.getToolCallbacks())
.call()
.content();
}
}toolCallbackProvider.getToolCallbacks()는 yml에 등록된 모든 MCP 서버의 도구를 한 배열에 모아 돌려준다. 사용자가 “12 더하기 30 계산해 줘”라고 입력하면 LLM은 calculator 서버의 add를 호출하고, “tmp 디렉터리 파일 목록 보여 줘”라고 하면 filesystem 서버의 list를 호출한다. ChatClient는 도구 결과를 모델에 다시 넣어 자연어 응답으로 받아낸다.
@Tool 어노테이션 하나로 일반 메서드를 LLM 도구로 바꾸기
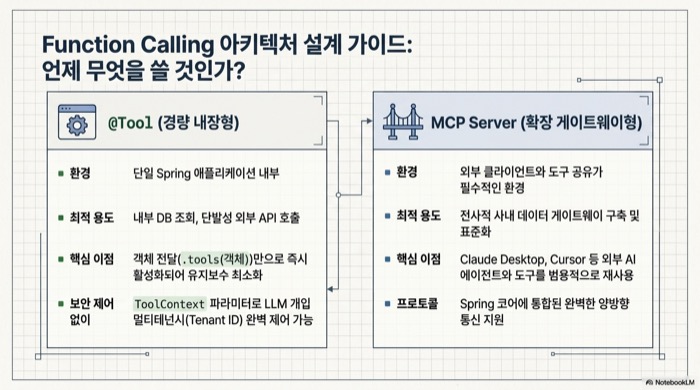
MCP 서버가 과한 상황에서는 같은 애플리케이션 안에서 @Tool 어노테이션을 붙인 메서드를 그대로 도구로 등록하는 편이 가볍다. ChatClient는 .tools(객체) 호출 한 번으로 객체 내 모든 @Tool 메서드를 ToolCallback으로 변환해 모델에 전달한다. 내부 데이터 조회나 단발성 외부 API 호출처럼 한 애플리케이션 내부에서 사용하는 도구라면 MCP 없이 충분하다.
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.ai.tool.annotation.ToolParam;
import org.springframework.context.i18n.LocaleContextHolder;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
class DateTimeTools {
@Tool(description = "사용자 시간대 기준 현재 시각을 ISO-8601 문자열로 반환한다")
String getCurrentDateTime() {
return LocalDateTime.now()
.atZone(LocaleContextHolder.getTimeZone().toZoneId())
.format(DateTimeFormatter.ISO_OFFSET_DATE_TIME);
}
@Tool(description = "지정한 시각에 알람을 설정한다")
void setAlarm(
@ToolParam(description = "ISO-8601 형식의 시각") String time) {
LocalDateTime alarmTime = LocalDateTime.parse(time, DateTimeFormatter.ISO_DATE_TIME);
System.out.println("알람 설정 완료: " + alarmTime);
}
}
// 호출 측 (chatModel은 자동구성된 ChatModel 빈을 주입받았다고 가정)
String response = ChatClient.create(chatModel)
.prompt("지금부터 10분 뒤에 알람 설정해 줘")
.tools(new DateTimeTools())
.call()
.content();@Tool(description=...) 값은 LLM이 어느 도구를 호출할지 판단하는 핵심 단서다. “현재 시각을 반환한다”보다 “사용자 시간대 기준 현재 시각을 ISO-8601 문자열로 반환한다”처럼 입력과 출력을 같이 적으면 모델이 setAlarm의 파라미터에 어떤 값을 넣어야 할지 더 정확하게 추론한다. 반환 타입이 void여도 동작하며, JSON Schema는 메서드 시그니처에서 자동 생성된다. 단 파라미터와 반환 타입에 Optional, CompletableFuture, Mono, Flux, Function, Supplier, Consumer는 못 쓴다. 이건 Tool Calling 공식 문서에 명시된 제약이다.
테넌트 ID처럼 컨텍스트성 정보를 도구 메서드에 전달해야 할 때는 ToolContext를 사용한다.
class CustomerTools {
private final CustomerRepository customerRepository;
CustomerTools(CustomerRepository customerRepository) {
this.customerRepository = customerRepository;
}
@Tool(description = "고객 ID로 고객 정보를 조회한다")
Customer getCustomerInfo(Long id, ToolContext toolContext) {
String tenantId = (String) toolContext.getContext().get("tenantId");
return customerRepository.findById(id, tenantId);
}
}
ChatClient.create(chatModel)
.prompt("42번 고객 정보를 알려 줘")
.tools(new CustomerTools())
.toolContext(Map.of("tenantId", "acme"))
.call()
.content();ToolContext 파라미터는 LLM에 전달되는 JSON Schema에서 자동으로 빠진다. 모델은 id만 보고 도구를 호출하지만, 실제 메서드는 tenantId까지 받는 식이다. 멀티테넌시 환경에서 LLM이 tenantId를 임의로 조작하지 못하게 막는 용도로 자주 쓴다.
LLM 응답을 어떻게 Java Record로 바로 받을 수 있을까
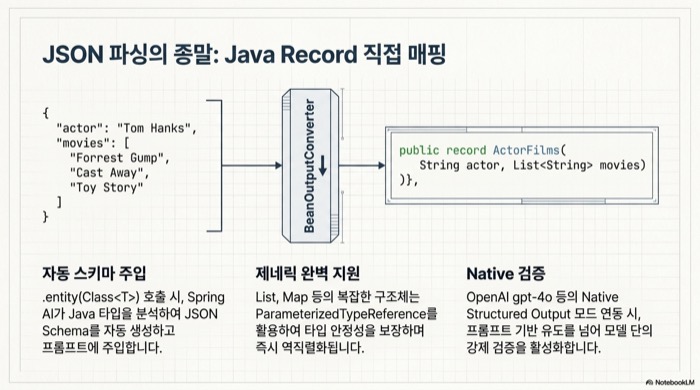
Spring AI 2.0에서는 ChatClient의 .entity(Class<T>) 호출 한 번이면 LLM 응답이 Java Record나 클래스로 역직렬화된다. 내부에서는 BeanOutputConverter가 Java 타입으로부터 JSON Schema를 만들어 프롬프트에 붙이고, 모델이 돌려준 JSON을 객체로 다시 매핑한다. OpenAI gpt-4o나 Claude 4 시리즈처럼 네이티브 structured output을 지원하는 모델은 모델 옵션의 responseFormat을 JSON Schema로 지정해 모델 측 강제 검증을 켤 수도 있다.
record ActorFilms(String actor, List<String> movies) {}
ActorFilms films = chatClient.prompt()
.user("아무 배우 한 명을 골라 대표 영화 5편을 알려 줘.")
.call()
.entity(ActorFilms.class);위 코드는 응답을 ActorFilms Record로 바로 받는다. Record 컴포넌트의 이름과 타입이 JSON 필드와 그대로 매핑되어 별도 매퍼 코드가 필요 없다. LLM 응답 모델은 한 번 만들어 던지고 끝나는 일회성 데이터가 많은데, Record는 이런 용도에 잘 맞는다.
리스트나 맵처럼 제네릭이 필요한 경우에는 ParameterizedTypeReference를 사용한다.
List<ActorFilms> filmsByActor = chatClient.prompt()
.user("Tom Hanks와 Bill Murray의 대표 영화 5편씩 알려 줘.")
.call()
.entity(new ParameterizedTypeReference<List<ActorFilms>>() {});이 호출은 두 배우 각각의 ActorFilms를 담은 리스트를 돌려준다. ChatClient가 ListOpenAiChatOptions.builder().responseFormat(ResponseFormat.builder().type(ResponseFormat.Type.JSON_SCHEMA).jsonSchema(...).build()).build() 형태로 빌더에 JSON Schema를 직접 지정한다. Anthropic 쪽은 별도의 JSON 모드 옵션 대신 tool use를 통해 JSON 응답을 유도하는 패턴이 일반적이다. 프롬프트만으로 유도하는 것보다 실패율이 낮다는 점이 가장 큰 차이다. 자세한 동작 원리는 Structured Output Converter 공식 문서에 정리돼 있다.
Spring AI 1.x에서 2.0으로 갈아탈 때 무엇을 깨뜨리는가
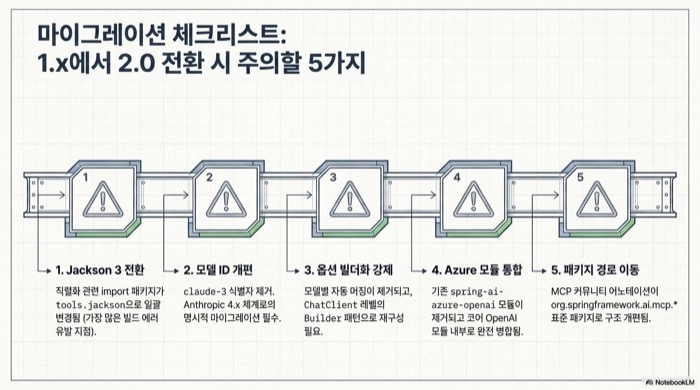
Spring AI 1.x에서 2.0으로 갈아탈 때 가장 자주 발목을 잡는 변경은 다섯 가지다. Azure OpenAI 모듈 통합, Anthropic 기본 모델 식별자 변경, ChatOptions 머징 위치 이동, Jackson 3 전환, MCP 어노테이션 패키지 변경이다. 컴파일이 깨지는 지점이 명확해서 하나씩 잡아 나가면 그렇게 어려운 일은 아니지만, 미리 알지 못하면 처음 BOM 버전을 올리는 순간 빌드 에러 수십 개가 한꺼번에 터진다.
| 변경 항목 | 1.x | 2.0 | 영향 |
|---|---|---|---|
| Azure OpenAI 모듈 | spring-ai-azure-openai | spring-ai-openai에 통합 | Azure 엔드포인트/배포명을 OpenAI 속성으로 재설정 |
| Anthropic 기본 모델 | claude-3.x 계열 기본값 | claude-sonnet-4-5 (M5 기본값) | 모델 미지정 호출의 응답 모델이 자동 변경, 명시 지정으로 고정 권장 |
| ChatOptions 머징 | 모델 레벨에서 자동 머징 | ChatClient 레벨로 이동, builder/customizer 사용 | 부분 옵션 객체를 builder로 재구성 |
| Jackson | 2 (com.fasterxml.jackson) | 3 (tools.jackson) | 직렬화/역직렬화 import 일괄 변경 |
| MCP 어노테이션 | org.springaicommunity.mcp | org.springframework.ai.mcp.annotation | import 패키지 일괄 변경 |
disableMemory() | disableMemory() | disableInternalConversationHistory() | deprecated shim 제공, 점진적 교체 가능 |
실무에서는 이 표를 기준으로 PR을 쪼개는 편이 변경 범위 파악에 편하다. BOM 버전부터 2.0.0-M5로 올리고 빌드 에러를 잡는 식으로 시작한 뒤, 모델 ID, 옵션 빌더, Jackson import 순서로 잡아 나가면 작업이 단순해진다. 항목별 변경 내역은 Spring AI 2.0 Upgrade Notes에 정리돼 있다.
FAQ
Spring AI 2.0 GA는 언제 나오는가?
2026년 5월 1일 기준 최신 마일스톤은 2.0.0-M5(4월 27일 릴리즈)이며 공식 GA는 아직 발표 전이다. 외부 보도에서는 5월 말경 GA가 예상된다는 정보가 돌고 있지만, 정확한 일정은 Spring AI GitHub Releases에서 확인하는 것이 안전하다. 마일스톤 단계에서는 https://repo.spring.io/milestone 저장소를 추가해야 의존성을 받을 수 있다.
Spring AI 2.0과 LangChain4j는 어떤 점이 다른가?
Spring AI 2.0은 Spring Boot 자동구성을 통해 ChatClient.Builder 빈을 바로 주입받을 수 있고, MCP 서버/클라이언트 통합이 코어에 포함된다. LangChain4j는 Spring과 무관한 표준 Java 라이브러리로 더 넓은 호환성을 가지지만, Spring 생태계와의 통합 강도는 Spring AI가 더 깊다. 이미 Spring 기반 백엔드라면 Spring AI를 우선 선택하는 편이 일관성 측면에서 유리하다.
MCP를 꼭 써야 하는가?
MCP는 외부 도구 게이트웨이가 필요할 때만 도입한다. 같은 Spring 애플리케이션 내부에서 도구를 정의해 LLM에 노출하는 경우라면 @Tool 어노테이션 만으로 충분하고, MCP 서버를 띄우는 비용이 오히려 과하다. Claude Desktop, Cursor 같은 외부 MCP 클라이언트와 도구를 공유해야 할 때 MCP 서버 도입 가치가 발생한다.
Spring AI 2.0이 Java 21에서도 동작하는가?
Spring AI 2.0은 Spring Boot 4.1을 기반으로 하므로 최소 요구 JDK는 Spring Boot 4.1 릴리즈 노트에 따른다. Spring Framework 7 베이스라인이 올라간 만큼 정확한 최저 버전은 Spring Boot 시스템 요구사항 페이지에서 확인하는 것이 안전하다. 실무에서는 Java 21 LTS 이상에서 Virtual Threads와 같이 운용하면 LLM 호출 같은 I/O 바운드 작업에서 스레드 자원을 크게 아낄 수 있다.
OpenAI 키가 없으면 로컬에서 테스트할 방법이 있는가?
Ollama 스타터(spring-ai-starter-model-ollama)를 사용하면 로컬에 설치한 LLM을 ChatClient로 호출할 수 있다. application.yml에 OpenAI 대신 Ollama 설정만 넣으면 ChatClient 호출 코드는 그대로 유지된다. 모델 추상화 덕분에 로컬 개발은 Ollama로, 운영은 OpenAI/Claude로 운영하는 듀얼 셋업이 쉽게 구성된다.
마무리하며

처음 Spring AI 1.x를 도입했을 때만 해도 ChatClient 빌더만 있어도 충분히 행복했다. 그러다 사내 인사 시스템 데이터를 LLM에 연결해야 하는 작업이 들어왔을 때, 자체 RestClient로 Function Calling을 구현하면서 토큰 사용량 추적과 재시도, 스트리밍 응답 처리를 직접 짜야 했고 그때마다 “이거 진짜 Spring 답게 한 줄로 안 되나” 싶었다. 2.0의 SyncMcpToolCallbackProvider를 처음 봤을 때 솔직히 좀 허탈했다. 오랫동안 짜고 있던 코드가 한 줄짜리 자동구성으로 끝나는구나 싶어서.
마일스톤 단계라 운영 환경에 곧장 올리기는 부담스럽지만, 신규 PoC 프로젝트라면 지금 시점에 2.0을 시작하는 편이 GA 후 마이그레이션 비용을 줄이는 길이라고 본다. 특히 MCP 서버/클라이언트 통합은 1.x로는 흉내내기 어려운 영역이라, AI 에이전트형 백엔드를 만드는 팀이라면 2.0 마일스톤을 미리 익혀두면 좋을 것이라 생각한다.